Counterfactual Multi-Agent Policy Gradients
Counterfactual Multi-Agent Policy Gradients
AAAI 2018
citations: 1949(2024-02-22)
1. Introdution
- 어떻게 해야 centralised learning의 특성을 최대한 살릴 수 있을 것인가?
- global reward만 쓰면 각 agent의 기여도를 분석하는데 어려움을 겪는다. 각 agent에 별도의 reward function을 부여하는 것은 성능이 좋지 않다. => credit-assignment (global reward를 각 agent의 기여도에 따라서 배분하는 것)를 어떻게 수행할 것인가?
위의 두 문제를 해결하기 위해 우리는 새로운 actor-critic 기법을 적용한 counterfactual multi-agent policy gradient를 제안한다.
1-1. Use a centralised critic
training중에는 joint action/state information으로 조건화된 critic와 오직 각 action-observation history로 조건화된 actor를 함께 사용하고 execution중에는 actor만 사용한다.
1-2. Use counterfactual baseline
Counterfactual baseline은 difference reward에서 영감을 받았다. difference reward란 각 agent가 기존 action을 통해 받는 global reward와 action을 default로 변경했을 때 받는 reward를 비교하며 그 action의 실제 가치를 학습하는 방식이다. Difference reward는 credit-assignment(Global reward를 각 agent의 기여도에 따라 배분하는 것)를 수행하는 강력한 방법이지만 변화한 action을 평가하기 위한 simulation이 추가적으로 필요하며 default action을 어떻게 정의할 것인지 명확하지 않다.
COMA는 agent-specific advantage function을 연산하기 위한 centralized critic을 사용함으로써 이를 해결한다. agent-specific advantage function이란 현재의 joint action으로 평가된 return에 다른 agents의 action은 고정해놓고 해당하는 agent action을 marginalize out(확률 분포에서 해당 변수를 제외하고 marginal distribution을 찾는 행위)한 counterfactual baseline을 빼주는 식으로 연산한다. 추가적인 simulations, 근사, default action에 대한 가정에 의존하는 대신 각 agent에 대해 별도의 baseline(기준)을 제시하는 것이다. 이 baseline은 특정 state에서 단일 agent가 가질 수 있는 모든 action에 대한 평균적 가치를 찾는 counterfactual을 추론하기 위해 centralized critic을 활용한다.
1-3. Use a critic representation
Counterfactual baseline을 single-forward pass로 효율적으로 연산하기 위해 critic representation을 사용한다. 다른 agent의 action으로 조건화된 특정 agent의 다른 모든 action에 대한 Q값을 계산한다. 모든 agent에 대해 단일 critic을 사용하기 때문에 모든 agent의 Q값을 single batched forward pass로 계산 가능하다. 각 agent별로 다른 critic을 사용하는 기존 방법과는 달리 효율적이다.
3. Background
가장 간단한 single-agent policy gradient methods REINFORCE 의 gradient는 아래와 같다.
\[\begin{aligned} J &= \mathbb{E}_{\pi}[R_{0}]\\ grad &= \mathbb{E}_{s_{0:∞},u_{0,∞}}[\sum^T_{t=0}R_t∇_{\theta^\pi}log(\pi(u_t|s_t))] \end{aligned}\]actor-critic 접근법에서 policy는 critic에 의존하는 gradient에 의해 학습된다.
\[\begin{aligned} grad &= \mathbb{E}_{s_{0:∞},u_{0,∞}}[\sum^T_{t=0}(Q(s_t,u_t)-b(s_t))∇_{\theta^\pi}log(\pi(u_t|s_t))]\\A(s_t,u_t) &= Q(s_t,u_t)-V(s_t) \end{aligned}\]b(s)는 variance를 줄이기 위한 baseline이다. 보통 b(s) = V(s)이다.
어떤 케이스에는 아래와 같이 R이 TD error로 변하기도 한다. Advantage function의 unbiased version이다. 일반적인 TD의 경우 V(st)에서 V(s(t+1))로 이동하는 action이 명확하게 정의되지 않기 때문에 bias가 발생하지만 해당하는 action이 활용 가능하다면 Advantage function에서 TD error를 활용하더라도 bias를 발생시키지 않는다.
\[\begin{aligned} R_t &= r_t+\gamma V(s_{t+1}) - V(s)\\ grad &= \mathbb{E}_{s_{0:∞},u_{0,∞}}[\sum^T_{t=0}(r_t+\gamma V(s_{t+1}) - V(s))∇_{\theta^\pi}log(\pi(u_t|s_t))] \end{aligned}\]COMA에서는 Q나 V를 평가하기 위해 TD(λ)-DNN을 사용해 on-policy critic을 학습시킨다.
\[\begin{aligned} critics &= f^c(·,\theta^c)\\ G^{(n)}_{t} &= \sum^{n}_{l=1} \gamma^{l-1}r_{t+l} + r^{n} f^c(·,\theta^c) \end{aligned}\]critic parameter θ^c는 아래의 loss를 따르는 mini-batch gradient descent에 의해 업데이트된다.
\[\begin{aligned} L_t(\theta^c) &= (y^{(\lambda)}-f^c(\cdot,\theta^c))^2 (2)\\ y^{(\lambda)} &= (1-\lambda)\sum^{∞}_{n=1}\lambda^{n-1}G^{(n)}_t \end{aligned}\]n-step return: G의 경우 target network에 의해 연산된 bootstrapped values이다.
4. Methods
Independent Actor-Critic (IAC)
각 agent가 저마다의 action-observation history로 조건화된 독립적인 actor/critic을 가지는 네트워크이다. COMA의 실험에서는 각 agent의 파라미터를 공유하여 단 하나의 actor/critic을 학습하고 모든 agent가 사용한다(하나의 공통 policy를 학습한다는 의미이다). 각 actor는 같은 policy를 가지지만 입력되는 observation 정보가 다르므로 각각 다른 action을 선택한다. critic은 오로지 u^a로 조건화된 local value function만을 추정한다. 논문은 2개의 IAC 변종을 고려하는데, 첫번째 critic은 V(history)를 평가하고 TD error를 기반으로 한 gradient를 따른다. 두번째 critic은 Q를 평가하고 Advantage function을 기반으로 한 gradient를 따른다(Background 참조).
IAC는 강력하지만 훈련동안 각 agent가 정보를 공유할 수 없으므로 협력을 학습하기 어렵고 각 agent가 기여한 정도를 파악할 수 없다. 아쉽게도 우리가 setting한 IAC 또한 learning이 centralized되어 있다는 사실을 활용하는데 실패했다.
Counterfactual Multi-agent Policy gradients
COMA는 이러한 IAC의 한계를 극복했다. 메인 아이디어는 다음과 같다. IAC에서는 각 actor가 \(\begin{aligned} \pi(u^a|\tau^a) \end{aligned}\) 각 critic이 \(\begin{aligned} Q(u^a,\tau^a) or V(\tau^a) \end{aligned}\)
를 학습한다. 그러나 critic은 train도중에만 필요하며 execution이 실행되는 도중에는 actor만 필요하다. learning이 centralized되어 있기 때문에 우리는 global state s로 조건화된 centralized critic or joint action-observation histories를 사용 가능하다. 각 actor는 파라미터를 공유하며 action-observation history를 사용해 조건화된다.각 actor가 centralized critic으로부터 추정된 TD Error에 기반한 gradient를 따르는 것은 쉬운 방법이다.
\[\begin{aligned} grad=∇_{\theta^\pi} log(\pi(u|\tau^a_t))(r+\gamma V(s_{t+1})-V(s_t)) \end{aligned}\]하지만 이런 식으로는 Credit assignment problem을 해결하기 힘들다. TD Error는 오직 global reward만을 고려하기 때문이다. 각 agent로부터 계산된 gradient는 특정 agent의 action이 global reward에 기여한다는 명시적인 이유가 되지 못한다. 다른 agent또한 exploration을 수행하기 때문에 각 gradient는 굉장히 noisy하고 이는 agent가 많아질수록 심해진다. 그러므로 COMA는 counterfactual baseline을 사용한다. 이는 각 agent가 shaped reward에 의해 학습하는 difference reward에 의해 영감을 얻었다.
U: u의 bold \(\begin{aligned} shaped reward:D^a = r(s,U) - r(s,(u^{-a},c^a)) \end{aligned}\)
difference reward는 global reward와 agent a의 action을 default action c^a로 바꾼 뒤 얻은 global reward를 비교해서 shaped reward를 얻는다. agent a의 action이 D^a를 향상시킨다면
\[\begin{aligned} r(s,(u^{-a},c^a) : baseline estimator \end{aligned}\]에 영향을 주지 않고 global reward r(s, U)를 향상시키기 때문이다. difference reward는 credit assignment를 수행 가능하며 강력하지만 baseline estimator가 각 agent마다 추가적인 reward를 연산해야 하기에 요구되는 Counterfactual simulation이 기하급수적으로 증가한다. simulation을 수행하는 대신 function approximation을 사용하려는 연구가 있었지만 이것 또한 user-specified default action c^a를 요구하며 agent가 많아질수록 적용이 어렵다. 또한 approximation이라는 방식은 추가적인 bias를 생성한다는 문제 또한 있다.
COMA의 key insight는 centralized critic을 통해 difference reward를 실행하면서도 이러한 문제를 피할 수 있다는 것이다. 학습중인 policy를 활용해 agent a가 현재 state에서 취할 수 있는 모든 action에 대해서 각각 global q값을 추정하고 action 확률에 따라 평균낸다. 즉, joint V값을 추정하는 것이다.
\[\begin{aligned} A^a(s,U) &= Q(s,U)-\sum_{u^{'a}}\pi^a(u^{'a}|\tau^a)Q(s,(U^{-a},u^{'a})) (3)\\ counterfactual baseline &= \sum_{u^{'a}}\pi^a(u^{'a}|\tau^a)Q(s,(U^{-a},u^{'a})) (4) \end{aligned}\]따라서 A는 각 agent에 대해서 자기 자신의 동작만이 변경되었을 때의 Counterfactual에 대해서 추론한다. 이는 agent의 experiences를 통해 직접 얻어내며 추가적인 simulations, reward model, default action에 대해 의존하지 않고 학습이 가능하다. 또한 aristocrat utility와 달리 policy와 utility function의 상호의존성에 빠지지 않는다. 이전의 연구는 difference reward의 추론을 위해 default action을 활용했지만 COMA에서 Counterfactual baseline의 grad에 대한 기여도 평균은 0이기 때문이다.
\[\begin{aligned} J(\theta)&=\mathbb{E}_{\pi_{\theta}}[r] \\ &=\sum_s d(s)\sum_a \pi_\theta(s,a)R_{s,a} \\ \end{aligned}\] \[\begin{aligned} ∇_\theta\pi_\theta(s,a) &= \pi_\theta(s,a)\frac{∇_\theta\pi_\theta(s,a)}{\pi_\theta(s,a)} \\ &= \pi_\theta(s,a)∇_\theta log(\pi_\theta(s,a)) \\ \end{aligned}\] \[\begin{aligned} ∇_\theta J(\theta) &= \sum_sd(s)\sum_a ∇_\theta\pi_\theta(s,a)R_{s,a}\\ ∇_\theta J(\theta) &= \sum_sd(s)\sum_a\pi_\theta(s,a)∇_\theta log(\pi_\theta(s,a))R_{s,a}\\ &=\mathbb{E}_{\pi_{\theta}}[∇_{\theta}log(\pi_\theta(s,a))r] \\ &=\mathbb{E}_{\pi_{\theta}}[∇_{\theta}log(\pi_\theta(s,a))Q^{\pi_{\theta}}(s,a)] \\ &≈ \mathbb{E}_{\pi_{\theta}}[∇_{\theta}log(\pi_\theta(s,a))Q_{w}(s,a)] \\ \\ Δ\theta &= \alpha∇_{\theta}log(\pi_\theta(s,a))Q_{w}(s,a) \\ \\ \end{aligned}\] \[\begin{aligned} B(s) &= V^{\pi_{\theta}}(s) \\ \mathbb{E}_{\pi_{\theta}}[∇_{\theta}log(\pi_\theta(s,a))B(s)] &= \sum_sd^{\pi_\theta}(s)\sum_a ∇_{\theta}\pi_\theta(s,a)B(s) \\ \mathbb{E}_{\pi_{\theta}}[∇_{\theta}log(\pi_\theta(s,a))B(s)] &= \sum_sd^{\pi_\theta}(s)B(s)∇_{\theta}\sum_a \pi_\theta(s,a) \\ &=0 \end{aligned}\]따라서 counterfactual baseline, A(s,a)는 policy에 종속적이지 않게 된다. COMA는 이러한 형태의 advantage function을 self-consistency 문제 없이 사용 가능하다.
물론 Counterfactual baseline은 critic이 추가적으로 simulation을 추론하도록 요구하지 않더라도, 추론 그 자체만으로 Neural network의 영향으로 연산량이 많아진다. critic network 출력노드의 개수는 아래와 같다.
\(action 종류^{agent의 수}\)
이 문제를 해결하기 위해 COMA는 Counterfactual baseline의 효과적인 추론을 가능하게 하는 critic representation을 사용한다. 다른 agent들의 action set을 해당되는 agent의 q-function이 출력값인 하는 network에 입력으로 넣는 것이다.
\(actionset: u^{-a}_t\)
이를 통해 훈련을 하면서 동시에 critic이 advantage function을 효과적으로 연산할 수 있으며 네트워크의 output을 U^n에서 U로 줄일 수 있다(각 agent마다 별도의 single forward 연산을 수행하므로 exponential하지 않다).
우리는 이 논문에서 discrete action space에 집중하지만 COMA는 (4)번식을 Gaussian policies and critic을 사용해 continuous action space로도 매우 쉽게 확장할 수 있다(자세한 수식은 논문 참조).
각 agent의 Counterfactual baseline은 비록 variance를 줄이더라도 gradient의 평균값에 영향을 주지 않는다. 평균값에는 영향을 주지 않지만 각 agent에 할당되는 값에는 영향을 끼치면서 Credit assignment를 수행하는 것이다. 따라서 COMA의 수렴에는 영향을 주지 않는다.
5. Experiment
Decentralised StarCraft Micromanagement.
논문에서는 여러 대칭적인 팀간의 경기기록을 고려한다. 적 팀은 합리적이지만 최적화되어있지 않는 수작업 휴리스틱을 사용하는 SC2 AI에 의해 제어된다. agent들은 이동[방향], 공격[적 id], 정지, noop의 집합에서 선택할 수 있다. Starcraft게임에서 유닛이 공격 action을 선택하면, 먼저 공격 범위내로 진입한 후 게임의 내장된 경로 탐색을 사용해 경로를 선택하고 공격한다. 이러한 강력한 공격-이동 매크로 액션은 제어 문제를 상당히 쉽게 만든다.
더 의미있는 benchmark를 생성하기 위해, 우리는 에이전트에게 유닛의 무기 사거리와 동일한 제한된 시야를 부여한다. 이는 중앙 집중식 starcraft 제어의 표준 설정과 달리 3가지의 효과를 가져온다.
- partial observability
- agent는 적 유닛이 공격 범위 내에 있을때만 공격할 수 있으며 sc2의 매크로 action을 사용할 수 없다.
- agent는 사망한 적과 범위 밖에 있는 적을 구별하지 못하며, 따라서 잘못된 공격 명령을 내려 아무런 action이 수행되지 않을 수 있다. 이로 인해 action space의 크기가 상당히 증가하며, 탐색과 제어의 어려움을 증가시킨다.
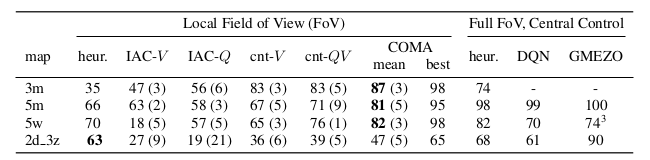
이러한 어려운 조건 하에서는 유닛 수가 비교적 적은 시나리오조차도 굉장히 어려워진다. 위의 표에서 볼 수 있듯이, 단순한 수작업으로 작성된 heuristic과 비교해보면, heuristic은 Full Field of View, Central control 환경의 5m 맵에서 98%의 승률을 달성하지만, 논문의 환경인 Local Field of View에서는 66%에 그친다. 이 환경에서 좋은 성능을 내기 위해서 는 에이전트들이 올바른 위치에 배치되고 공격을 집중해야하며, 살아있는 적과 아군 유닛을 구별해야 한다.
rewards: 모든 agent들은 각 time step에서 동일한 global reward를 받으며, 이는 상대 유닛에 가한 피해의 합에서 받은 피해의 절반을 뺀 값들이다. 상대를 처치하면 10점의 보상을 받으며, 게임에서 승리하면 팀의 남은 총 체력에 200을 더한 보상을 받는다.
input: State feature들은 actor/critic이 각각 local observations/global state에 해당하는 다른 입력 특징을 받는다. 둘 다 아군과 적에 대한 특징을 포함한다.
local observation features: 각각의 agent에 대한 local observation은 해당 agent가 제어하는 유닛을 중심으로 한 원형 지도의 일부에서만 추출된다. 이 지역 내의 각 유닛에 대한 관찰은 다음과 같은 정보를 포함한다. 거리, 상대적 x/y 좌표, 유닛 유형, shield, 모든 feature는 각각의 최대값으로 정규화된다. 유닛의 현재 목표에 대한 정보는 포함되지 않는다.
global state features: 시야에 상관없이 맵 상의 모든 유닛을 대상으로 한다. x/y좌표는 특정 agent가 아닌 맵을 기준으로 제공된다. 모든 agent의 체력 포인트와 쿨다운(공격 쿨타임)도 포함된다. centralized Q-critic에 전달되는 표현은 global state features와 local observation features를 결합한 것이다.
Architecture & Training
Actor는 128-bit gate의 GRU로 구성되어 있으며 input을 처리하고 hidden state에서 output을 생성하기 위해 FC-layer를 사용한다. IAC critic들은 actor network의 마지막 layer에 추가된 output head를 이용한다. action probability는 최종 layer인 z를 통해 제한된 softmax를 통해 생성되며 어떤 action의 확률의 하한이 epsilon/U로 제한된다(만약 epsilon=0.1이라면 softmax값에 90% 비중을 부여하고 나머지 10%를 모든 action에 고르게 분배하여 확률을 보정한다).
\[\begin{aligned} P(u) = (1-\epsilon)softmax(Z)_{u} + \epsilon/|U| \end{aligned}\]우리는 750개의 train episode동안 epsilon을 0.5에서 0.02로 줄여나간다. centralized critic은 여러개의 RELU layer와 FC-layer를 결합한 feed-forward network이다. hyper-parameter는 5m 시나리오에서 대략적으로 튜닝한 후 다른 모든 맵에 사용되었다. 저자는 TD(λ)라는 매개변수가 가장 민감하다는 것을 발견했고 COMA와 기준 모델 모두에서 가장 잘 작동하는 λ=0.8로 결정했다.
Ablations
-
IAC-Q, IAC-V 두 가지 IAC 변형과 비교하며 critic을 centralize하는 중요성을 테스트한다. 이러한 critic은 actor와 동일한 decentralized input을 받으며, 마지막 layer까지 actor network와 parameter를 공유한다. IAC-Q는 U개의 action value값을 출력하는 반면, IAC-V는 single state value값을 출력한다. 참고로, agent간에는 여전히 parameter를 공유하며, egocentric observation과 ID를 policy의 입력으로 사용해 다양한 action이 나타날 수 있도록 한다. reward function은 여전히 모든 agent에게 공유된다.
-
Q 대신 V를 학습하는 것의 중요성을 검증한다. Central-V방법은 여전히 critic을 위해 centralized state를 사용하지만 V(s)를 학습하고 TD Error를 policy gradient update에 대한 추정에 사용한다.
-
우리의 Counterfactual baseline의 유용성을 테스트한다. Central-QV 방법은 Q,V를 동시에 학습하며, advantage를 Q-V로 추정하며 COMA의 Counterfactual baseline을 V로 대체한다. 모든 방법은 actor에 대해 동일한 구조와 훈련 방식을 사용하며 모든 critic은 TD(λ)로 훈련된다. Central-QV는 joint Q, V를 구해서 Advantage function을 구하지만 COMA는 single forward pass를 활용해 각 agent별로 별도로 V를 근사해낸다는 차이가 있다.
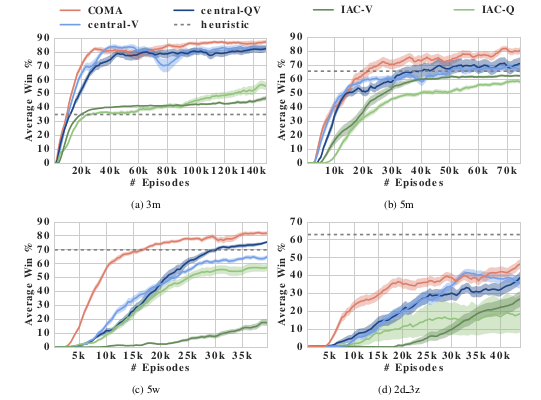
위의 사진(Figure 3)은 네 가지의 다른 시나리오에서 COMA와 경쟁 알고리즘의 승률을 보여준다. COMA는 모든 baseline보다 우수한 성능을 보인다. 또한, centralized critic들은 decentralized critic에 비해 명확히 우수한 성능을 보인다.
6. Results
Figure 3는 각 방법과 StarCraft 시나리오에 대한 episode별 평균 승률을 보여준다. 각 방법에 대해 35개의 독립적인 시도를 수행하고 학습 100-train step마다 중단하여 학습된 정책을 200개의 에피소드에 걸쳐 평가한다. 그리고 에피소드의 평균값을 산출하고 이를 바탕으로 시도의 평균값을 도출한다. 또한 표준편차를 이용한 신뢰구간도 표시된다. 즉, 68%정도의 확률로 그래프 실험 범위로 들어오는 것이다. 결과적으로 COMA가 모든 시나리오에서 IAC 기준선보다 우수한 성능을 보인다는 것을 보여준다. 흥미로운 점은 IAC 방법들도 결국 5m에서 합리적인 정책을 학습하지만, 이를 위해서는 훨씬 더 많은 에피소드가 필요하다는 것이다. IAC 방법들의 actor/critic network가 초기 layer에서 parameter를 공유하기 때문에 학습속도가 빨라질 것으로 기대할 수 있으나 이러한 결과는 global state로 조건화된 policy 추정이 각각 별도의 network를 훈련하는 데 필요한 연산 작업에 비해 학습속도에 우위를 가지게 해준다는 것을 나타낸다.
또한 COMA는 모든 설정에서 훈련 속도와 최종 성능 모두에서 central-QV를 엄격하게 압도한다. 이는 centralized Q critic을 사용해 decentralized policy를 학습할 때 counterfactual baseline이 매우 중요함을 나타낸다.
State value function을 학습하는 것은 당연히 joint-action에 대한 조건부가 필요하지 않다는 장점이 있다. 그럼에도 불구하고 COMA는 최종 성능에서 Central-V baseline보다 우수한 성능을 보인다. 또한, COMA는 일반적으로 빠른 학습 속도를 달성하며, 이는 COMA가 형태화된 train signal을 제공하기 때문에 예상되는 결과이다. 학습은 central-V보다 안정적이며, 이는 policy가 greedy하게 변할 때 COMA gradient가 0으로 수렴하는 결과이다. 전체적으로 COMA는 가장 우수한 방법이다.
Conclusions
본 논문은 COMA policy gradient라는 방법을 소개한다. 이 방법은 centralized critic을 사용해 decentralized policy에 대한 counterfactual advantage를 얻어내는 방법이다. COMA는 MARL에서 발생하는 multi-agent credit-assignment 문제를 해결하기 위해, 다른 agent들의 action을 고정시키고 한 agent의 모든 가능한 action을 고려한 counterfactual baseline을 사용한다. 논문은 분산된 Starcraft2 Micromanagement benchmark에서의 결과를 통해, COMA가 다른 MARL Actor-Critic 방법에 비해 최종 성능, 훈련 속도를 크게 개선시키며, 최고 성능 조건에서 중앙화된 컨트롤러와 경쟁력을 유지한다는 것을 보여준다.
Leave a comment