cs231n Lecture6 Training Neural Network1
Activation Functions
Activation Function은 XW에 대해서 input이 들어오면, 다음 노드로 보낼 때 어떻게 보낼지를 결정해주는 역할을 한다. 여기서 중요한 점은 Activation fucntion은 필수적인 요소이며 비선형 형태여야 Network를 깊게 쌓을 수 있다는 것이다.
Activation function이 없는 경우 A1 = W1X1+b1
A2 = W2A1+b2 = W2(W1X1+b1) + b2 = W2W1X1+W2b1 + b2 = WX1+B
어차피 A1과 같은 형태가 나와 Network를 깊게 쌓는다 해도 의미가 없다.
Activation Function이 선형인 경우
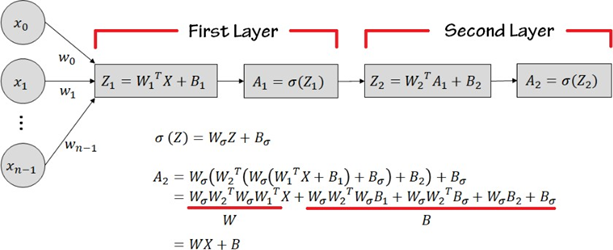
Network가 깊어져도 WX+B로 정리 가능하므로 layer를 깊게 쌓을 필요가 없다.
1. Sigmoid function
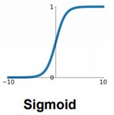
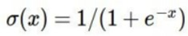
sigmoid함수는 3가지 문제가 존재해서 더 이상 Activation Function으로 사용되지 않는다.
Problem 1: gradient vanishing(기울기 소실)
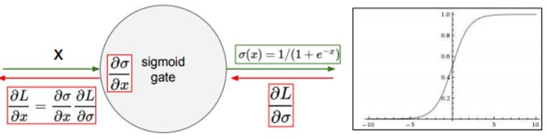
Sigmoid 함수의 입력값이 일정 이상 커지거나 작아지면 기울기가 거의 0에 가까운 것을 알 수 있다. 또한 기울기의 최대값이 0.5이므로 역전파가 진행될 때마다 gradient가 급격하게 작아진다는 문제가 있다.
Problem 2: Non zero-centered
Sigmoid 그래프를 보면 원점을 중심으로 되어 있지 않다는 것을 확인할 수 있다. 즉, 모든 input에 대해서 양수 값으로 output이 나오게 된다.

𝛛a/𝛛z의 범위는 [0,𝟏], 𝛛z/𝛛w2 의 범위는 [0,1]이므로 𝛛𝐋/𝛛w 는 요소가 모두 양수이거나 음수인 행렬이 된다.
즉 3개의 chain rule 요소 중에서 1개만 부호를 결정할 수 있으므로 W2 업데이트 방향은 모두 같은 부호를 가진 행렬로 생성된다. 𝛛𝐋/𝛛w2 의 구성이 [+, +], [-, -]만 존재한다고 가정해보자.
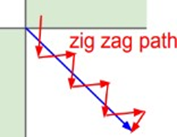
최종적인 목적지에 도달하기 위해서는 [-, -]방향(4사분면 방향) => [+, +]방향(1사분면 방향) => [-, -]방향으로 비효율적으로 움직이게 된다. 만약 [+, -]가 존재할 수 있다면 완벽한 3사분면 방향으로 뻗어나갈 수 있으나 sigmoid함수는 이걸 불가능하게 만든다.
Problem 3: compute expensive of exp()
지수 연산은 연산에 시간이 오래 걸리기 때문에 컴퓨터 입장에서는 그다지 좋지 않은 연산이다.
2. tanh function
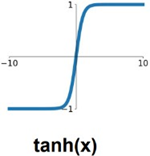
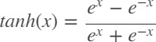
sigmoid의 단점을 개선해서 zero-centered된 tanh를 사용했으나 양 끝에서 발생하는gradient vanishing, 지수 연산의 문제가 있어 잘 사용하지 않는다.
3. ReLU function (rectified linear unit)
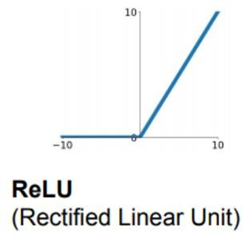

가장 표준적인 activation function으로 두 선형 함수의 합으로 생각할 수 있다. 성능이 좋아 현재에도 많이 사용하지만 ReLU함수에도 문제점은 존재한다.
Problem 1: Non zero-centered
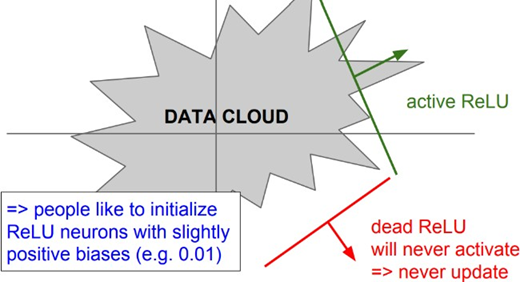
ReLU함수가 Data cloud와 겹치지 않을 경우에, 즉 데이터가 활성 함수를 활성화시키지 못한다면 dead ReLU가 발생할 수 있다.
Problem 2: 0 이하의 값들은 모두 버려짐 절반의 gradient는 죽는다는 것이다.
이러한 ReLU함수의 문제를 보완하기 위해 다양한 ReLU 패밀리들이 나오게 된다.
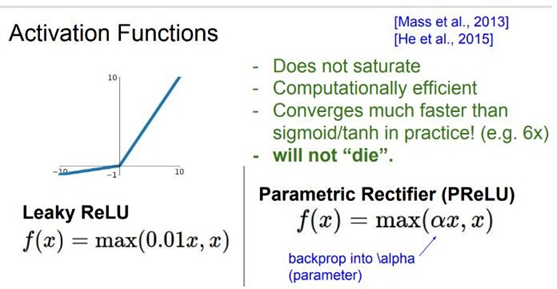
먼저 Leaky ReLU는 위의 그래프와 같이 죽지 않는다. 또한 parametric Rectifier의 경우 α 계수를 파라미터처럼 컨트롤 할 수 있다.

ELU는 ReLU와 Leaky ReLU의 사이라고 쉽게 이야기할 수 있다. ELU는 기존의 dying ReLU 현상을 방지하며, 또한 거의 zero-center에 가깝게 존재한다. 한 마디로 ReLU의 장점만 모아놓은 함수다. 하지만 유일한 단점으로 exp()연산을 수행해야한다는 점이 있다.
일반적으로 Relu와 Leaky Relu를 많이 사용하고, 필요에 따라 ELU의 방법을 고려해보는 것이 좋다. 그리고 Tanh는 RNN, LSTM에서 자주 사용하지만 CNN에서는 사용하지 않는다고 한다. 그리고 sigmoid는 절대 사용하지 않는다.
Data Preprocessing
수집한 데이터를 모델에 입력하기 전에 컴퓨터가 해석하기 좋은 형태로 가공하는 과정이다.
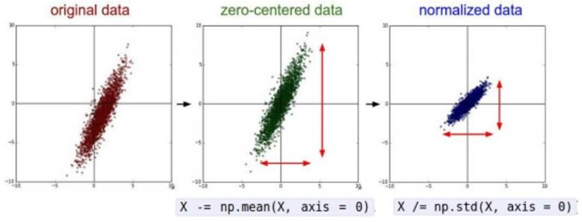 그러나 이미지 분석에서는 normalization할 필요가 없이 Zero-centered data로만 만들면 된다. 입력 이미지 데이터는 각 차원이 이미 특정 범위 안에 들어있기 때문이다. 이미지 처리는 원본 이미지 자체의 spatial 정보를 활용해 이미지의 spatial structure를 얻는다.
그러나 이미지 분석에서는 normalization할 필요가 없이 Zero-centered data로만 만들면 된다. 입력 이미지 데이터는 각 차원이 이미 특정 범위 안에 들어있기 때문이다. 이미지 처리는 원본 이미지 자체의 spatial 정보를 활용해 이미지의 spatial structure를 얻는다.
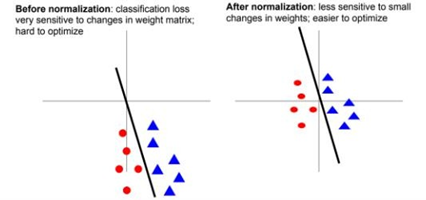
만약 데이터가 normalizaiton이 안되어 있고 Zero centered가 되어 있지 않으면 선이 조금만 틀어져도 분류를 잘못할 위험이 더 커진다. W의 변화에 Loss function이 민감해지는 것이다. 이것은 Data preprocessing의 이유이자 Batch Normalization의 이유이기도 하다.
그러나 data preprocessing 과정에서 Zero-centered는 sigmoid 특유의 Non-zero centered 문제를 해결할 수 없다. 첫 번째 layer의 input value로 Zero centered된 데이터를 입력해도 다음 layer부터는 같은 문제가 반복되기 때문이다. 이 문제는 Batch Normalization을 통해 어느정도 해소 가능하다. 여기서 중요한 것이 데이터 분포를 Batch normalization한다고 해서 값이 가지고 있는 특징적인 의미가 사라지는 것은 아니라는 것이다.
Weight Initialization
Weight가 어떻게 초기화 되♘는지에 따라 학습의 결과에 영향을 줌으로 매우 중요한 영역이다. 만약 모든 W의 요소가 0으로 초기화된다면 symmetric breaking이 발생하지 않는다. symmetric breaking이란 model이 random한 weight값을 갖게 하여 모델이 대칭적인 output value를 출력하는 것을 막아내는 것이다.

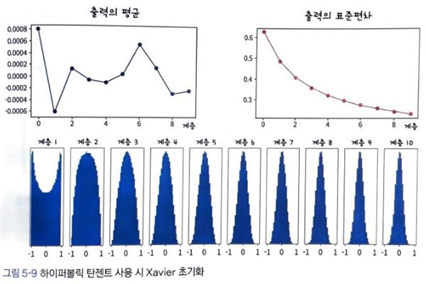
초기화 문제를 해결하는 첫번째 방법은 w를 임의의 작은 값으로 초기화하는 것이다. 0을 평균으로 하고 표준편차가 0.01인 Gaussian 정규분포에서 초기 W를 sampling해보면 작은 Network에서는 symmetry breaking되긴 하지만 보다 깊은 네트워크에서는 큰 문제가 생긴다. 아래 3개의 그래프는 layer-activations의 관계를 여러 방법으로 표현한 것이다.
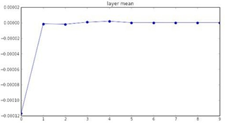
각 layer의 activation mean이 1번째 layer부터 거의 0에 가까워진다. 이는 tanh함수가 Zero- centerd함으로 발생하는 현상이다.
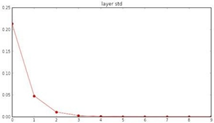
그러나 activation의 standard deviation이 3-layer부터 거의 0이되어 모든 activations가 0이 되♘다. 이는 W가 너무 작아 대부분의 Activations가 layer를 지날 때마다 0에 빠르게 가까워짐을 알 수 있다.

또한 forward pass 과정에서 정규분포 형태로 존재하던 activation값들이 3-layer부터 모두 0으로초기화 되었음을 알 수 있다. 이러한 forward pass의 흐름을 보면 gradient update가 일어나지 않을 것임을 짐작할 수 있다. W에 관해 편미분을 하고 싶으면 X값이 필요한데 x값에 해당하는 activation들이 0에 가까워지기 때문이다. 그렇다면 W를 평균이 0이고 표준편차가 1인 Gaussian 정규분포에서 샘플링해보면 어떨까?

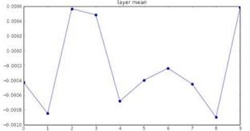
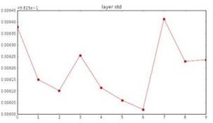

활성 함수의 입력 값이 매우 커지거나 작아져 Activations가 거의 모두 -1, 1로 초기화된다. 이는 활성 함수의 입력 좌표 지점에서의 기울기가 0이 되게 만들어 거의 모든 gradient를 0으로 초기화한다. 이처럼 적절한 W를 구하는 것은 매우 어려운 일인데, 그렇다면 어떻게 W를 초기화해야 할까?
Xavier initialization
Xavier Initialization은 sigmoid 계열의 activation function을 사용할 때 가중치를 초기화하는 방법이다. Input data의 분산이 output data에서 유지되도록 가중치를 초기화한다.
가정1. Input data가 0근처의 작은 값으로 되어 있어 sigmoid 계열의 activation function의 가운데 선형적인 부분을 지나므로 잠시 activation function이 선형 함수라고 가정을 해보자.
가정2. Input data와 weight는 서로 독립, Input data의 각 차원은 같은 분포이고(input data는 각 feature 마다 data들이 동일한 어떤 분포를 가진다) 서로 독립인 iid(independent identically distribution, 독립항등분포)를 만족한다. 각각의 random variable들이 독립이며, 동일한 확률분포를 가지는 분포형태라는 뜻이다. 여기서 random variable은 input data의 feature를 의미한다. Weight는 standard normal distribution(표준정규분포)의 형태로 초기화된다.
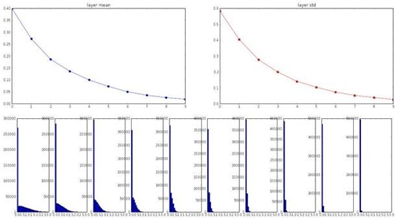
Xavier 초기화는 가중치의 분산이 input data의 개수 n에 반비례하도록 초기화하는 방식이라고 해석할 수 있다. 그런데 이 상황에서는 variance의 최대값이 1이다. Input data는 1이상의 정수 이기 때문이다. 따라서 variance는 0~1의 범위를 가지는데 이 영역에서 Standard deviation은 variance에 비해 감소하는 속도가 느려진다. 어찌되든 var이 감소하면 std도 감소하는 관계다.
따라서 input data가 적어질수록 standard deviation은 상대적으로 커져 standard normal distribution의 그래프가 보다 더 옆으로 퍼진다. 초기화되는 W의 값들이 확률적으로 커지는 것이다. Xavier 초기화를 이용해서 신경망을 초기화 했을 경우, layer를 통과해도 산이 잘 유지되고 있다.
 \(Variance = \frac{1}{fan\,in}\)
따라서 input data의 수에 따라 표준 정규분포의 분산을 조절해 W값들이 유연하게 출력되도록 하여 layer를 통과해도 variance가 잘 유지되도록 한다. 결과적으로 Gradient Vanishing이 사라져 신경망의 학습이 잘 진행된다.
\(Variance = \frac{1}{fan\,in}\)
따라서 input data의 수에 따라 표준 정규분포의 분산을 조절해 W값들이 유연하게 출력되도록 하여 layer를 통과해도 variance가 잘 유지되도록 한다. 결과적으로 Gradient Vanishing이 사라져 신경망의 학습이 잘 진행된다.
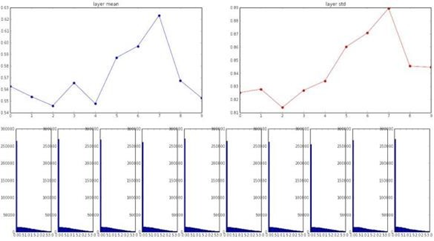
하지만 이 방식은 비선형 함수인 ReLU를 활용하면 다시 문제가 발생한다. Xavier는 선형 함수를 가정하기 때문에 비선형 함수에서는 문제가 발생할 수 있는 것이다. zero-mean 함수였던 tanh와 다르게 ReLU는 음수 부분이 전부 0으로 출력되기 때문에 위와 같은 그래프가 나타난다. Activation function을 지나면서 편차가 강제로 절반으로 줄어들게 되는 것이다. Layer가 깊어질수록 standard deviation(표준 편차)가 0에 가까워지는 것이 그 증거다. 출력 값이 0이 많다면, W의 update는 잘 이루어지지 않을 것이다.
 \(Variance = \frac{2}{fan\,in}\)
여기서 우리는 fan_in을 2로 나눠서 분산을 2배 더 커지게 해 W값의 분포가 전체적으로 더 커질 수 있도록 해준다. 이를 통해 Xavier는 더 넓은 초기값 가중치 분포를 얻게 된다. 뉴런의 절반이 죽어버린다는 근거로 2를 더 나눈 것이다. 그래프를 보면 마지막 layer에도 activations가 살아있다는 것을 알 수 있다.
\(Variance = \frac{2}{fan\,in}\)
여기서 우리는 fan_in을 2로 나눠서 분산을 2배 더 커지게 해 W값의 분포가 전체적으로 더 커질 수 있도록 해준다. 이를 통해 Xavier는 더 넓은 초기값 가중치 분포를 얻게 된다. 뉴런의 절반이 죽어버린다는 근거로 2를 더 나눈 것이다. 그래프를 보면 마지막 layer에도 activations가 살아있다는 것을 알 수 있다.
Batch normalization
Gradient descent는 gradient를 한번 업데이트하기 위해 모든 train data를 사용한다. 즉 학습 데이터 전부를 넣어서 gradient를 다 구하고 한번에 모델을 업데이트하는 것이다. 이런 방식으로 하면 대용량의 데이터를 처리하지 못하기 때문에 dataset을 batch 단위로 나눠서 학습하는 방법을 사용하는 것이 일반적이다. 그래서 등장한 것이 SGD이다.
Stochastic Gradient Descent에서는 gradient를 업데이트 하기 위해서 dataset의 일부(batch의 size)만을 활용한다. 즉, 학습 데이터 전체를 한번 학습하는 것을 Epoch, Gradient를 구하는 최소 data집합 단위를 Mini-Batch라고 한다.
Batch 단위로 학습을 하게 되면 Internal Covariant shift라는 문제점이 발생한다. 학습 과정에서 Batch단위로 입력의 데이터 분포가 달라지는 현상을 의미한다. MLP, CNN에서 feature를 입력으로 받아 연산을 거친 뒤 activation function을 적용하게 되면 input data와 activations가 달라질 수 있다. 또한 Batch 단위 간에 데이터 분포의 차이가 발생할 수 있다.
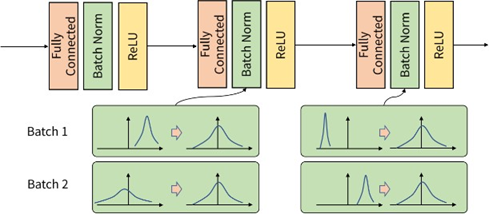
Batch Normalization은 각 배치 단위 별로 데이터가 다양한 분포를 가져도 각 mini-batch별로 평균과 분산을 활용해 normalization하는 것을 뜻한다. 위 그림을 보면 batch단위나 layer에 따라서 입력 값의 분포가 모두 다르지만 정규화를 통해 분포를 Zero mean Gaussian(정규분포), 평균이 1, 표준 편차가 1인 데이터의 분포로 조정할 수 있다.
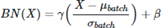
Batch Normalization은 학습 단계와 추론 단계에서 조금 다르게 적용된다. Train 단계에서 γ는 스케일링 역할을 하고 β는 bias다. 둘 다 parameter로서 역전파를 통해 학습된다. 이 때 계산되는 평균과 분산은 mini batch별로 묶여서 계산된다.

어떤 layer에서 행렬 곱 연산을 수행한 N개의 D차원 input data(Mini-batch 1)가 있다고 보자. 우리는 화살표대로 각각의 차원(feature)마다 mean과 variance를 연산할 수 있다. 계산한 mean과 variance로 normalize를 한다. 이게 한 Mini-batch 단위에서의 normalize다.
각각의 층에서 가중치 W들이 이전 layer의 activations와 곱해지기 때문에 layer를 지날 때마다 범위가 크게 bounce될 수 있다. 따라서 FC연산이 종료된 후 batch norm을 넣어주어 normalize를 진행한다. 만약 Activation Function이 tanh이라면 Batch Norm은 tanh의 입력값들을 tanh 함수의 gradient 가 linear한 부분으로 범위를 강제하는 것(saturate)이라고 표현할 수 있다.
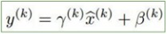
Normalize한 x의 값을 다시 identity값으로 변경하고 싶을 경우 감마를 곱해준 뒤, 베타를 더해주는 위 함수를 활용한다. 이렇게 saturate(포화)의 상황을 좀 더 유연하게 control할 수 있게 된 것이다. 상황에 따라 batch norm의 효과가 무조건 좋다고 보장할 수는 없기 때문이다.
batch normalization을 적용하면 weight의 값이 평균이 0, 분산이 1인 상태로 분포가 되어 이 상태에서 ReLU가 activation으로 적용되면 전체 분포에서 음수에 해당하는 (1/2 비율) 부분이 0이 되어버린다. γ, β는 정규 분포의 형태를 scaling하고 평행 이동시켜 ReLU에서 많은 부분이 죽어버리지 않도록 방지하는 역할을 한다.
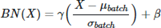
추론 과정에서는 평균과 분산에 고정 값을 사용하는데 학습 단계에서는 데이터가 배치 단위로 들어오기 때문에 배치의 평균, 분산을 구하는 것이 가능하지만, 테스트 단계에서는 배치 단위로 평균/분산을 구하기가 어려워 학습 단계에서 배치 단위의 평균/분산을 저장해 놓고 테스트 시에는 평균/분산을 사용한다.
Batch norm은saturate(현 데이터의 분포 상태)를 흐릴 수 있냐는 질문이 있을 수 있으나 Batch Normalization은 그저 data를 scaling, shifting 해주는 것이기 때문에 데이터의 구조는 바뀌지 않는다. 선형 변환이기 때문에 공간 구조가 무너지지 않는다고 생각하면 이해하기 쉽다.
Babysitting the Learning Process
Network의 Architecture(Deep Leaning의 구조)를 구성하고 학습과정을 어떤 시각으로 바라봐야 하는지, 그리고 hyperparameter를 어떻게 조정하는지 전체적인 프레임을 살펴볼 것이다.
-
first step: data 전처리
-
Network의 Architecture를 구성한다
-
MLP, CNN같은 Architecture중 기초 model 결정 2-2. loss, regularization, hyper-parameter 결정
-
Train set에서 일부만 가져와서 시작 -> overfitting이 되면 학습이 잘되는 것을 확인
-
전체 데이터를 학습시키며 Loss를 확인하면서 Learning rate를 조정함
#### Hyper-parameter(HP) Optimization
앞으로 우리가 중점적으로 tuning해야하는 HP는 learning rate와 regularization이다. 2장에서도 K-NN알고리즘의 K-tuning과 관련해 HP 최적화를 다룬 적이 있다. 취할 수 있는 한가지 전략은 바로 cross-validation이다. Cross-validation은 Training set으로 학습시키고 Validation set으로 평가하는 방법이다. HP를 좀 더 단계적으로 찾아보자.
우선 coarse stage(학습 초기)에서는 넓은 범위에서 값을 골라낸다. Epoch 몇 번 만으로도 현재 값이 잘 동작하는지 알 수 있다. NaN(Not a number)이 뜨거나 혹은 Loss가 줄지 않거나 하는 것을 보면서 이에 따라 적절히 잘 조절할 수 있을 것이다. coarse stage가 끝나면 어느 범위에서 잘 동작할 것인지 대충 알게 된다. 두 번째 fine stage(model을 보다 세밀하게 최적화하는 단계)에서는 좀 더 좁은 범위를 설정하고 학습을 좀 더 길게 시켜보면서 최적의 값을 찾는다. NaN으로 발산하는 징조를 미리 감지할 수도 있다. Train 동안에 Cost가 어떻게 변하는지를 살펴보는 것이다.
이전의 cost 값보다 더 커지거나 한다면, 가령 이전보다 cost가 3배 높아졌다거나 한다면 잘못 하고 있는 것이다. Cost값이 엄청 크고 빠르게 오르고 있다면 loop를 멈춰버리고 다른 HP를 선택하면 된다. HP의 적절한 값을 찾는 다른 방법으로는 Grid search, Random search 방식이 사용된다. Learning rate는 일반적으로 gradient와 곱해지기 때문에 빠르게 수렴하는 영역과 더 섬세하게 수렴하는 영역 사이를 탐색하면서 좀 더 효과적으로 최적값을 찾도록 10의 거듭제곱 단위로 설정된다.
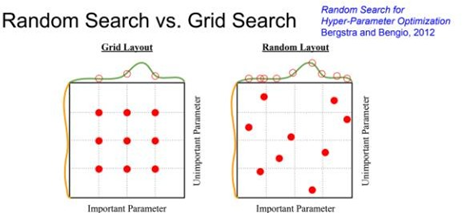
둘 사이에서는 Grid search보다는 Random Search방식이 더 좋은 성능을 보이는데 그리드 방식은 일정 간격으로 조합을 찾기 때문에 모든 HP의 중요도를 똑같이 설정하지만 랜덤 방식은 이러한 벽이 없기에 더 나은 가능성을 보여준다. 몇 번씩 반복해보면 HP의 범위를 좁히는 insight를 얻을 수 있다. parameter들마다 sensitivity가 다른데, learning rate는 굉장히 sensitive하지만 regularization은 그렇지는 않다. HP의 최적화는 정말 다양한 방법이 있으며 감으로 시작해서 범위를 좁혀나가는 방식으로 이해하는 것이 직관적이다.
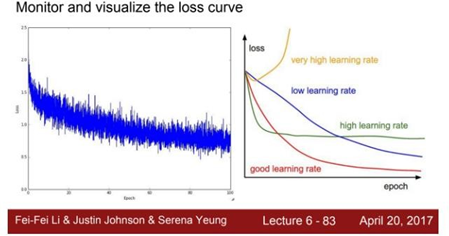
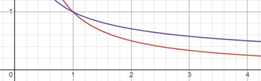
Learning rate값은 Update의 속도와 방향의 정확도를 모두 겸비한 빨간색의 그래프가 best이다.
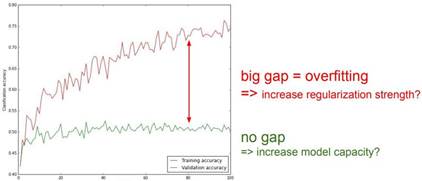 Validation set의 accuracy값과 training set의 accuracy값의 차이가 크면 안된다. 차이가 크다는 것은 곧 train set에 대한 overfitting이 일어난 것이다. 이 경우 regularization의 강도를 높여주는 방식을 생각할 수 있다.
Validation set의 accuracy값과 training set의 accuracy값의 차이가 크면 안된다. 차이가 크다는 것은 곧 train set에 대한 overfitting이 일어난 것이다. 이 경우 regularization의 강도를 높여주는 방식을 생각할 수 있다.
Leave a comment