cs231n Lecture5 Convolutional Neural Networks
abstract
5강에서는 본격적인 Convolution Neural Network에 대한 설명을 시작한다. 우선 기존 MLP와는 input data를 제공하는 방식이 다름을 이해하며 FC-layer 대신 filter를 이용한 partial connection, Convolution 연산 후 출력되는 activation map에 대해서도 배운다. 후에 Convolution 연산을 위 한 잡 기술 stride, Zero padding에 대해서도 배우며 마지막에는 Pooling 연산에 대해 간략이 설 명한다.
Convolution Neural Network
우리는 지금까지 위 사진과 같은 FC(fully connected)구조를 활용했♘다. 하지만 이미지를 판별할 때는 별로 좋지 못한 성능을 가지고 있다. 그 이유는 여러가지가 있는데
첫째, 길게 늘어진 column vector가 curse of dimensionality(차원의 저주)를 유발하기 때문이다.
둘째, DNN은 위치 정보를 고려하지 않기 때문에(행렬을 열 벡터로 변환하는 과정에서 위치정보 가 희석됨)학습 이미지가 조금만 shift되거나 distortion(왜곡)되면 다른 이미지라고 인식할 확률 이 높다. 따라서 학습해야 할 이미지들의 양이 엄청나게 늘어난다.
셋째, FC구조는 굉장히 많은 양의 parameter(행렬 W의 요소)가 발생하게 된다. 따라서 학습에 걸 리는 시간이 굉장히 증가하게 된다.
첫 번째의 단점과 세 번째의 단점을 결합하면 overfitting(과잉적합)이 일어나기 굉장히 좋은 조 건이 된다. Curse of Dimentionality로 인해 항상 학습 데이터가 충분하지 않게 되며 지나치게 많 은 양의 parameter는 별 차이가 없는 test data조차 training dataset과 다르다고 할 확률이 높게 된다.
쉽게 설명하자면 바나나를 인식할 때 판단하는 기준이 모양, 색깔 2가지인 모델과 각기 다른 1000가지의 판단 기준이 존재하는 모델의 성능을 비교했을 때 너무 많은 판단 기준을 가진 모델 은 입력 데이터에 대해 지나치게 많은 판단 기준을 적용해 오히려 정확도가 떨어질 수 있다는 것 이다.
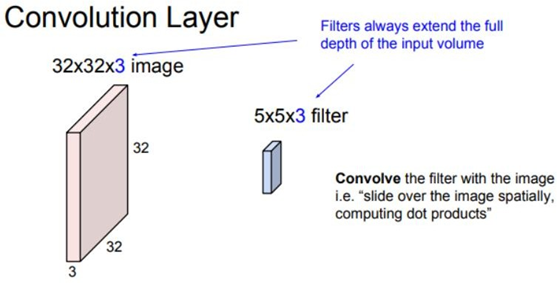
여기에 Filter를 활용해 input image에서 특징을 뽑아낼 것이다. 이때 주의할 것은 filter의 depth 와 image depth가 항상 동일해야 한다는 것이다. Filter는 합성곱연산을 통해 하나의 지역에 대해 하나의 값을 뽑아낸다. 결과적으로 28X28X1 크기의 activation map이 나오게 된다.
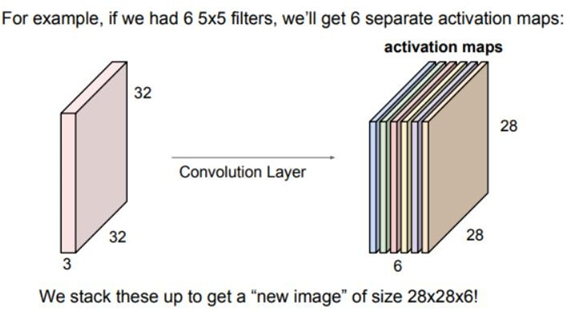
파란색 필터 말고 초록색 필터를 이용해 특징을 뽑으면 새로운 activation map이 나오게 된다. 만일 6개의 필터가 있다면 6개의 activation map이 출력될 것이다. 이때 parameter의 개수는 필 터 하나당 필터의 크기에 bias를 더한 \(Height * width * depth+1\) 만큼 생성된다. Filter의 개수가 늘어난다면 필요한 parameter의 개수도 덩달아 증가하게 된다.
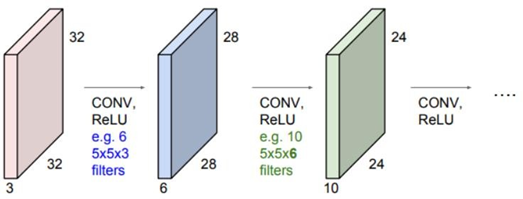
위와 같은 과정을 반복해서 Convolution layer를 쌓을 수 있다.
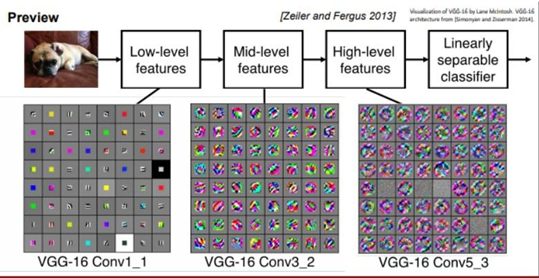
Features를 시각화 하면 아래층으로 갈수록 더 자세한 영역을 다루는 것을 확인할 수 있다. 초기 CNN은 convolution layer -> activation function -> Pooling layer가 반복되는 구조를 가진다.
7X7인 input data에 3X3 filter를 한번씩 sliding한다면 5X5 output activation map이 생성된다. 1 번씩 이동하지 않고 2칸, 3칸씩 이동할 수도 있는데 이때 움직이는 간격을 stride라고 하며 stride 1, stride 2라고 부른다. 7X7 input data에 3X3 filter, stride 2를 적용하면 3X3 activation map이 만들어질 것이고, stride 3인 경우 filter가 이미지에 딱 떨어지지 않게 된다. 아래와 같은 공식을 이해하자. \(𝑎𝒄𝒕𝒊𝒗𝒂𝒕𝒊𝒐𝒏\,𝒎𝒂𝒑\,𝒉𝒆𝒊𝒈𝒉𝒕, 𝒘𝒊𝒅𝒕𝒉 = \frac{N-F}{stride} + 1\) 여기서 (N-F)/stride가 분수인 경우 내림 연산을 수행할 수 있다.
Zero padding (pad)
Zero padding이란 Input data의 가장자리에 Zero값을 둘러주어 input image의 크기를 늘려주는 것이다. Convolution 연산을 할 때마다 activation map의 크기는 점점 줄어들게 되는데 이로 인 해 activation map의 depth가 깊어질 수 없게 된다. 따라서 Zero padding을 통해 input data의 크기를 키워주는 것이다. 또한 input data의 side에 있는 데이터들은 Conv 연산 특성상 중심부분 보다 더 적게 연산을 수행하므로 특징이 손실되거나 왜곡될 수 있는데 이 문제 또한 부분적인 해 결이 가능하다는 것도 장점이다.
1X1 filter

Filter의 크기가 1X1X64라면 Filter 수에 따라 output의 depth는 달라지지만 기존 이미지의 가로 세로 size는 유지된다. 이때 filter의 개수를 input dimension(64)보다 작게 하면, dimension reduction의 효과가 있으므로 차원 축소의 효과를 가지기 위해 1X1XN 필터를 사용할 수 있다.
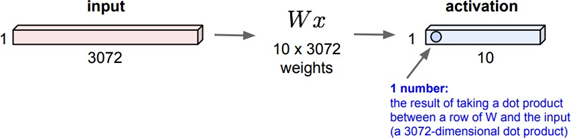
FC의 경우 하나의 output이 모든 input에 대한 특징을 가지고 있다.
Pooling
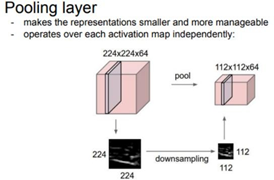
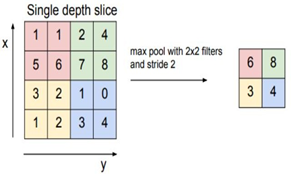
Pooling은 image의 특징을 유지하며 크기를 줄이는 역할을 한다. 주로 Max POOLING을 많이 사용하는데, 숫자가 큰 값만 남겨 둔다는 뜻은 가장 큰 특징 값만 뽑는다고 생각할 수 있다.입력 이미지의 size를 줄이는데 사용한다.이러한 과정을 반복하면 결국에 1X1XN의 activation map이 출력되는데 이를 FC-layer의 입력값으 로 사용하여 이미지를 분류하게 된다.
Leave a comment