cs231n Lecture12 Visualizing and Understanding
abstract
이번 강의에서는 CNN의 각 layer가 어떤 task를 수행하는지, CNN의 Black Box를 들여다볼 것이다. Input Layer와 output layer뿐만 아니라 각 hidden layer를 시각화하는 다양한 방법을 알아볼 것이다. 또한 gradient ascent라는 새로운 개념을 통해 새로운 image를 생성하는 방법의 일종인 feature inversion과 textual synthesis를 활용해 style transfer model로 창의적인 image를 생성해볼 것이다.
Overview
지금까지는 CNN을 어떻게 학습시킬 것인지를 배웠다. 그리고 다양한 Task에 대응하기 위해서 CNN Architecture를 어떻게 설계하고 조합해야 하는지를 배웠다. 이제 우리가 해야 할 질문은 바로 CNN의 내부가 어떻게 생겼냐는 것이다. CNN은 다양한 문제를 어떻게 해결하는 것일까? CNN은 어떤 종류의 Feature를 찾고 있는 것일까?
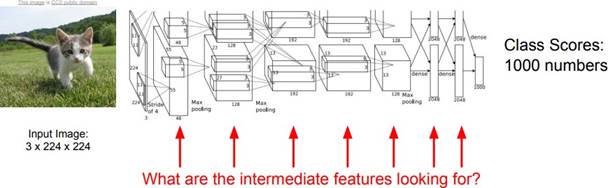
Input image를 CNN에 input하면 여러 Conv layer를 지나며 다양한 변환을 거쳐 우리가 해석할 수 있는 Class score, Labeled pixels, Bounding Box의 좌표와 같은 형태로 출력된다. 그렇다면 CNN layer의 black box에서는 무슨 일이 일어나고 있는가? 각 layer는 무엇을 찾고 있는 것일까?
Visualizing: First Layer - weight

1번째 layer부터 분석을 시작해보자. AlexNet의 각 Conv1 filter는 3X11X11의 형태를 띈다. 각 filter는 sliding window로 input image의 일부 영역을 순회하며 내적 연산을 수행한다. 이렇게 filter의 weight와 내적을 수행한 결과가 Conv1 Activation map이다. AlexNet의 Conv1 layer는 64개의 filter가 존재하며 input image와 직접 내적 연산을 수행하기 때문에 이 filter를 단순히 Visualizing하는 것만으로 이 filter가 image에서 어떤 feature를 찾는지 알아낼 수 있다.
우선 filter에서 가장 많이 찾는 feature는 흑백으로 길게 늘어선 edge이고 다양한 각도와 위치에서의 opposing color(보색)들도 보인다. opposing color란 빛의 삼원색(RGB) model에서 두 색상이 함께 합쳐졌을 때 흰색을 만들어내는 색상을 의미한다. 따라서 image에서 높은 대비를 가지는 부분을 표현하는데 유리하다. 흥미로운 점은, CNN을 어떤 model/data로 학습하든 layer 1은 전부 다 이런 pattern을 추출한다는 것이다.
Visualizing Middle Layer - weight

이제 Layer 2의 weight를 살펴보자. 위 사진은 작은 Conv Network이다. Conv2 layer는 16 channel (depth)의 input을 받는다. 여기서 각각의 channel은 layer 1에서 진행한 내적 연산을 통해 출력한 depth가 1인 Activation map으로 RGB 정보를 포함하고 있다. Layer 2의 filter들은 직접적으로 image의 형태로 시각화 시킬 수 없다는 문제점이 있다. filter들을 직접 살펴본 것만으로는 이해할 만한 정보를 얻기 힘들다는 것이다.
여기서 layer 2의 input image는 depth가 16인 7X7크기의 activation map이다. 이 activation map의 각각의 channel은 layer 1에 있는 16개의 filter를 거쳐 model의 input image의 edge, opposing color에 관한 정보를 가지고 있다. Layer 2는 이 input data에 대해 16X7X7 filter를 20개 적용할 것이다. 이 20개의 16X7X7 filter들을 시각화하기 위해서는 16개의 7X7 grayscale(흑백) images로 나눈 뒤 각 image들을 0~255의 범위로 normalize를 진행하고 표현해야 한다. weight는 범위가 정해져 있지 않으므로 scale을 조정해야 하기 때문이다. Bias까지 고려하지 않았기 때문에 위 image를 너무 믿으면 안된다.
Layer 1에서 edge, opposing color에 대한 특징을 이미 추출했으므로 layer 2부터는 edge, opposing color로부터 보다 더 고차원의 추상적인 특징을 추출하기 때문에 layer 2에서부터 filter를 시각화하는 것으로는 유의미한 정보를 얻을 수 없다. 결국 Conv layer, FC-layer는 입력된 특징을 다른 차원에서 해석하는 작업을 수행하는데 이를 인간이 시각적으로 해석하기엔 무리가 있다.
아무리 자세히 봐도 이 filter가 어떤 feature를 원하는지 적당한 intuition을 얻기 어렵다. 이 filter들은 image와 직접 연결되어 있지 않고 Layer 1의 출력과 연결되어 있기 때문이다. 따라서 우리가 Visualizing한 Layer 2 filter의 내용은 Layer 1의 출력에서 특별하게 나타나는 시각적인 pattern이 무엇인지 분석한 것이다. 하지만 image의 관점에서 Layer 1의 출력이 어떻게 생겼는지 해석하기란 쉽지 않다. 따라서 middle layer에 있는 filter들이 무엇을 찾고 있는지 알아내기 위해서는 조금 더 fancy한 기법이 필요하다. 이제 마지막 Layer를 분석해보자.
Visualizing: Last Layer – input data
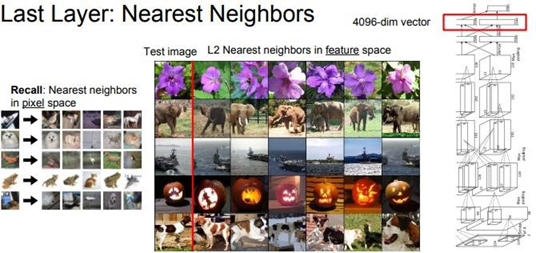
Last layer의 출력에는 Train data의 predicted score를 의미하는 1000개의 class score가 있다. AlexNet의 경우 이 마지막 Layer의 input으로 4096-dim 특징 벡터를 받는다. CNN의 마지막 layer 에서 어떤 일이 일어나는지 분석하는 것도 Visualizing의 한 방법이 될 수 있다.
방법 1은 “image pixel space”와 “feature vector space”를 비교하는 것이다. 먼저 많은 image로 CNN을 돌려서 각 image에서 나온 4096-dim 특징 벡터를 모두 저장한다. 왼쪽의 image는 CIFAR-10 data들의 “image pixel space”에서의 Nearest Neighbor였다. “image pixel space”란 각 image가 pixel값으로 표현되는 공간을 의미한다. 결과를 보면 유사한 image를 잘 찾아내는 것을 볼 수 있다. 맨 왼쪽의 column이 CIFAR-10으로 학습시킨 image이다. 오른쪽의 5개 column의 image들은 test data이다. 2번째 row의 흰색 강아지의 예를 들어보자. Pixel space 에서 Nearest Neighbor는 흰색 덩어리가 있으면 굳이 개가 아니더라도 가깝다고 생각할 것이다. 다만 last layer는 “image pixel space”에서 Nearest Neighbor를 연산하는 것이 아니라 CNN에서 나온 4096- dim “feature vector space”에서 연산한다. 맨 왼쪽 column은 ImageNet의 test dataset이다. 그리고 다른 image들은 AlexNet의 4096-dim “feature vector space”에서 연산한 Nearest Neighbors 결과이다. 이 결과들을 보면 확실히 “image pixel space”에서의 Nearest Neighbors와는 완전히 다르다. “image pixel space”에서 pixel값의 차이가 크더라도 “feature vector space”내에서는 아주 유사한 특징을 가질 수 있다는 것을 알 수 있다. 예를 들어 2번째 row의 코끼리가 좌우 반전되어 “image pixel space”에서 차이가 크더라도 “feature vector space”내에서는 아주 가까운 image가 될 수 있다는 것이다. 이는 Network가 학습을 통해 image의 semantic contents, 즉 image의 의미, 내용을 이해하는데 관련된 feature들을 잘 포착했다는 것을 의미한다. 이처럼 Nearest Neighbor를 통한 시각화 기법은 어떤 일이 일어나는지 살펴보기에 아주 좋은 방법이다.
방법 2는 Last layer에서 어떤 일이 일어나는지 visualizing할 때 Dimension Reduction(차원 축소)의 관점으로 분석하는 것이다. Principle Component Analysis(PCA)를 적용시켜서 고차원의 4096-dim feature vector를 2-dim으로 압축시키는 방법이다. PCA는 curse of dimensionality를 막기 위해 dataset의 feature 수를 줄이는 Data preprocessing기법이다. 이 방법을 통해 고차원 특징 공간을 직접적으로 Visualizing할 수 있다. PCA로도 이런 일을 할 수 있지만 t-SNE 알고리즘이 더 효과적이다.

t-SNE는 t-distributed stochastic neighbor embedding이라는 뜻이다. Data의 분포를 유지하면서 고차원의 data를 저차원으로 변환해 Visualizing하는데 뛰어난 성능을 보여주는 기법이다. 이 시각화 기법은 특징 공간 분포의 모양을 보여주는 것이 아니다. 그저 특징이 어떤 식으로 모여 있는지 관찰하기 위함이다. 옆의 사진은 MNIST dataset을 t-SNE dimensionality reduction를 통해 시각화한 모습이다. t-SNE가 MNIST의 784- dim data를 input으로 받아 2-dim으로 압축한 뒤 MNIST를 Visualizing한다. 이런 방법을 Conv layer의 input인 4096-dim feature vector에도 적용할 수 있다. 이를 통해 학습된 feature space의 기하학적인 모양도 추측해볼 수 있다. 결국 원본 image를 CNN을 활용해 4096-dim feature vector를 추출하고 t-SNE를 활용해 2-dim으로 추상화한 것이다. 이런 Dimension reduction을 통해 feature space에는 일종의 불연속적인 의미론적 개념(semantic notion) 이 존재한다는 것을 알 수 있다.
Visualizing: Middle Layer – activation map
앞서, middle layer에 있는 weight를 visualizing한다고 해도 이를 해석하기는 쉽지 않다고 말했다. 하지만 middle layer의 weight가 아니라 Activation map을 시각화해보면 일부 해석할 수 있는 것들을 볼 수 있다. 다시 AlexNet의 예시를 살펴보자. AlexNet의 Conv5는 13 x 13 크기의 filter를 사용하여 128X13X13-dim tensor의 activation map을 생성한다. tensor는 128개의 13X13 2-dim grid로 볼 수 있다. 따라서 이 1X13X13 tensor를 grayscale image로 visualizing할 수 있다. 이를 visualizing하면 Conv layer가 input data에게서 어떤 feature를 찾고 있는지를 짐작해볼 수 있다.
Visualizing: Middle Layer – Maximally Activating Patches
Middle layer의 feature를 visualizing할 수 있는 다른 방법이 있다. 어떤 image가 들어와야 각 neuron의 activations가 커지는지 시각화해보는 방법이다. AlexNet의 Conv5 layer를 예로 들겠다.

AlexNet의 Conv5는 128 x 13 x 13 한 덩어리의 activation volume을 갖는다. 우리는 128개의 channel 중에서 하나(17번째)를 뽑은 후 각 pixel을 neuron으로 지정할 것이다. 이 neuron들은 같은 channel이므로 이 layer에 속한 하나의 filter를 사용해서 제작했을 것이다.
이제 많은 image를 CNN에 통과시킨다. 그리고 각 image의 Conv5 activations를 기록해 놓는다. 그리고 나서 어떤 image가 17번째 feature map을 최대로 활성화했는지 살펴본다. 그리고 현재 이 neuron(activation map 17의 각 grid)은 image에서 receptive field에 해당하는 image의 일부만을 본다. 따라서 특정 layer의 feature를 최대화시키는 image의 일부(patches)를 visualizing할 것이다. 그리고 특정 neuron의 활성화 정도를 기준으로 patch들을 정렬시킨다.
오른쪽에 예시가 있다. 오른쪽에 보이는 patch들이 바로 해당 layer의 활성을 최대화시키는 patch들이다. 각 row에 있는 patch들이 하나의 neuron에서 나온 것이다. 각 patch들은 dataset에서 나온 patch들을 정렬한 값들이다. Patch의 feature를 통해서 해당 neuron이 무엇을 찾고 있는지 짐작해볼 수 있다. 가령 row 1을 보면 activation map 17의 한 pixel(neuron)이 image에서 어떤 동그란 모양을 찾고 있다는 것을 알 수 있다. 그리고 다른 row를 살펴보면 다양한 색상의 문자를 찾는 neuron도 있다. 또는 다양한 edge를 찾는 neuron이 있다는 것도 알 수 있다.
그리고 오른쪽 아래의 예시들은 Network의 더 깊은 layer에서 Neuron들을 최대로 활성화시키는 patch들이다. 이들은 더 깊은 layer에서 왔기 때문에 Receptive field가 훨씬 더 넓다. Receptive field가 더 넓으므로 image에서 수용 가능한 patch의 크기가 커진다. 따라서 이들은 input image에서 훨씬 더 큰 patch들을 기준으로 찾고 있다. 이를 이용해 우리는 재미있는 실험을 해볼 수 있다.
Occlusion(폐색) experiment

이 실험에서 알고자 하는 것은 input의 어떤 부분이 classification을 결정짓는 근거가 되는지에 관한 것이다. 우선 input image로 코끼리를 넣는다. 그리고 image의 일부를 가린 뒤 가린 부분을 dataset의 평균 값으로 채워버린다. 그리고 가려진 image를 Network에 통과시키고 Network가 이 image를 예측한 확률을 기록한다. 그리고 이 occluded patch(가림 패치)를 전체 image에 대해 slide하면서 같은 과정을 반복한다. 오른쪽의 heat map은 image를 가린 patch의 위치에 따른 Network의 예측 확률의 변화를 의미한다. 이 experiment의 idea는 특정 occluded patch를 input 했을 때 Network의 score 변화가 크다면 가려진 부분이 분류를 결정짓는데 아주 중요한 부분이♘다는 사실을 짐작할 수 있다는 것이다. 빨간색 지역은 확률 값에 영향을 크게 미치는 부분이고 노란색 지역은 확률 값에 영향을 낮게 미친다는 것을 의미한다. 이 방법도 사람이 Network가 무엇을 하고 있는지를 이해할 수 있는 아주 훌륭한 시각화 방법이다. 이와 관련된 또 다른 idea가 있다. “Saliency Map” 과 관련된 idea이다.
Saliency Map
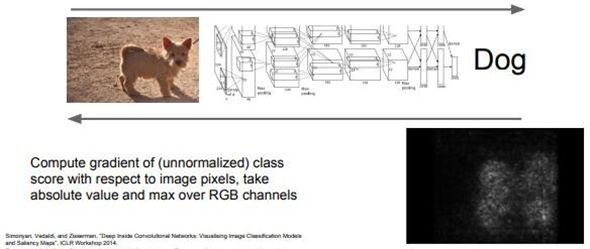
이 방법은 input image의 각 pixel들에 대해서 예측한 class score의 gradient를 계산하는 방법이다. 이 방법은 일종의 “1차 근사적 방법”으로 어떤 pixel이 영향력 있는지를 알려준다. 우리는 Input image의 각 pixel에 대해서, 우리가 그 pixel을 조금 조정했을 때 class score가 어떻게 바뀔지 궁금하다. 이 질문은 어떤 pixel이 “개”를 분류하는데 있어서 어떤 pixel들이 필요한지 알 수 있는 또 다른 방법이 될 수 있다. 이 방법을 통해 “개” image의 Saliency map을 만들어보면 “개”의 윤곽이 나타남을 알 수 있다. 이는 Network가 image에서 어떤 pixel들을 찾고 있는지를 짐작할 수 있다.
Saliency Map을 semantic segmentation에도 사용할 수 있다. Segmentation label 없이 saliency map만 가지고 semantic segmentation을 수행할 수 있다는 것이다. 이들은 Grabcut Segmentation Algorithm을 이용한다. Grabcut은 간단히 말해 interactive segmentation algorithm이다. 이 Saliency Map과 Grabcut을 잘 조합하면 이미지 내에서 객체를 Segmentation할 수 있다. 하지만 그렇게 잘 작동하지는 않는다. Supervision(감독)을 가지고 학습을 시키는 Network에 비해서는 안좋다.
Guided backpropagation
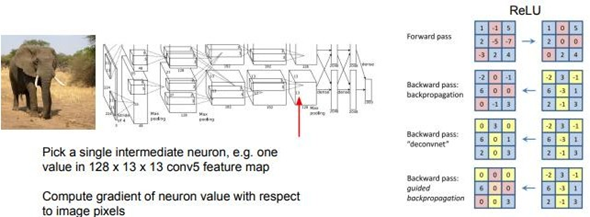
또 다른 Visualizing idea로는 guided backpropagation(BP)이 있다. 어떤 image가 있을 때 이제는 class score가 아니라 Network의 중간 Neuron을 하나 고른다. 그리고 input image의 어떤 부분이, 내가 선택한 중간 Neuron의 값에 영향을 주는지를 찾는 것이다. 쉽게 말해 saliency map은 각 pixel이 class score에 미치는 영향을 수치화한다면 Guided backpropagation은 pixel이 neuron(activation map의 각 grid)에 미치는 영향을 분석한 것이다.
이 경우에도 앞서 했던 방법처럼 Saliency map을 만들어볼 수 있다. 이 경우에는 image의 각 pixel에 대한 class score의 gradient를 연산하는 것이 아니라 input image의 각 pixel에 대한 Network 중간 Neuron의 gradient를 계산한다. 이를 통해 어떤 pixel이 해당 Neuron에 영향을 주는지 알 수 있다. 이 경우에도 평범한 backpropagation을 이용한다. 이 backpropagation 과정에서 조금의 트릭을 가미하면 조금 더 깨끗한 image를 얻을 수 있다. 이를 “guided backpropagation”이라고 한다. 2014년 논문이다. 이 방법은 backpropagation시 ReLU를 통과할 때 조금의 변형을 가해준다. Gradient의 부호가 양수이면 그대로 통과시키고 부호가 음수이면 진행하지 않는 방법이다. 이로 인해 전체 Network 가 실제 gradient를 이용하는 것이 아니라 양의 gradient만을 고려하게 된다. 이 방법에 대해서 이 이상 깊게는 들어가지 않겠다. 실험 결과를 보면, guided Backpropagation이 그냥 backpropagation에 비해 훨씬 더 선명하고 좋은 image를 얻을 수 있음을 알 수 있다.

왼쪽의 사진은 “Guided backpropagation”을 활용해 “maximally activating patches”처럼 image의 특정 patch에서 어떤 부분이 activation pixel값에 영향을 미치는지 시각화한 것이다. 이 patch들은 input image 에 어떤 pixel들이 특정 neuron에 영향을 미치는지를 알려준다. “maximally activating patches”와 비교해 볼 때 특정 patch에서도 어떤 부분의 neuron이 더 중요하게 작용했는지를 알 수 있다.
앞서 “maximally activating patches” 파트에서 이와 비슷한 시각화 기법을 살펴봤다. “maximally activating patches” 기법 외에도 “guided backpropagation” 이라는 방법을 통해서 patch의 어떤 부분이 neuron에 영향을 미치는지 알 수 있다. 위 사진의 row1을 보면 이 neuron이 아마도 둥그런 것들을 찾고 있음을 짐작해볼 수 있다. Guided backpropagation 결과를 살펴보면 방금 전 “maximally activating patches”를 통해 우리가 짐작했던 intuition을 어느정도 확신할 수 있다. 실제로 이미지 상의 둥근 부분들이 neuron의 실제 값에 영향을 미치고 있음을 직접 확인할 수 있기 때문이다. 이렇게 guided backpropagation은 중간 layer가 무엇을 찾고 있는지를 이해하기 위한 image를 생성하는데 아주 유용하다. 하지만 guided backpropagation이나 saliency map을 연산하는 방법들은 입력된 input image에 대한 연산을 수행할 뿐이다. 이 방법들은 고정된 input image, 혹은 input patch의 어떤 부분이 해당 neuron에 영향을 미치는지를 말해준다. 그렇다면 input image에 의존적이지 않은 방법은 없을까? 해당 neuron을 활성화시킬 수 있는 어떤 일반적인 input image가 있을까? 란 질문을 할 수 있다. 이에 대한 질문은 “Gradient ascent”라는 방법이 해답을 제시해줄 수 있다.
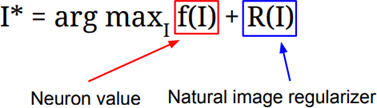
우리는 지금까지 Loss를 최소화시켜 Network를 학습시키기 위해 gradient descent를 사용했다. 하지만 여기서는 Network의 가중치들을 전부 고정시킨다. 그리고 Gradient ascent를 통해 중간 neuron 혹은 class score를 최대화시키는 image의 pixel을 만들어낸다. Gradient ascent는 Network 의 가중치를 최적화하는 방법이 아니다. 가중치들은 모두 고정되어 있다. 대신 neuron, class score 를 극대화할 수 있도록 input image의 pixel 값을 바꿔주는 방법이다. 이 방법에는 regularization term이 필요하다.
우리는 지금까지 regularization terms의 역할을 weight들이 train data로의 overfitting을 방지하기 위함으로 배웠다. 이 경우에도 유사하다. 고정된 가중치를 통해 생성된 image가 특정 Network의 특성에 완전히 overfitting되는 것을 방지하기 위함이다. Regularization term을 추가함으로서, 우리는 생성된 image가 두 가지 feature를 따르길 원하는 것이다. 하나는 image가 특정 neuron 의 값을 최대화시키는 방향으로 생성되길 바라는 것이고, 그리고 다른 하나는 image가 자연스러워 보여야 한다는 것이다. 생성된 image가 자연 영상에서 일반적으로 볼 수 있는 image 이길 바라는 것이다. 이런 류의 regularization term의 목적은 생성된 이미지가 비교적 자연스럽도록 강제하는 역할이다. 앞으로 다양한 regularization들을 살펴볼 것이다.
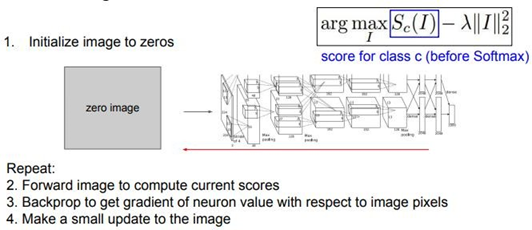
Gradient Ascent를 위해서는 초기 image가 필요하다. 이 image는 zeros initialization으로 모든 pixel의 값이 0로 초기화되거나 uniform initialization으로 모든 pixel의 값이 균등하게 random하게 초기화되거나 noise initialization으로 모든 pixel의 값이 작은 random noise로 초기화 시켜준다. 초기화를 하고 나면 image를 Network에 통과시키고 우리가 관심있는 neuron의 score를 계산한다. 그리고 image의 각 pixel에 대한 해당 neuron score의 gradient를 연산해 역전파를 수행한다. 여기서 Gradient ascent를 이용해서 image pixel 자체를 update한다. 해당 neuron의 score를 최대화시키는 것이다. 이 과정을 계속 반복하고 나면 아주 멋진 image가 탄생한다.

여기에서도 이미지에 대한 regularizer를 언급하지 않을 수 없다. 여기에서는 단순하게 생성된 이미지에 대한 L2 norm을 계산해서 더해준다. 사실 L2 norm을 추가하는 것 자체에 큰 의미가 있는 것은 아니다. Gradient Ascent와 같은 이미지 생성과 관련된 방법들의 초창기 문헌에서 종종 보이는 regularizer 중 하나일 뿐이다. 이 Network를 학습시켜보면 가령 왼쪽 상단의 dumbbell의 score를 최대화시키는 image가 생성된다. 그리고 생성된 image를 살펴보면 여러 dumbbell의 모양이 중첩된 채 생성되♘음을 알 수 있다. 그리고 생성된 컵의 image를 보면 다양한 컵들이 중첩된 image를 볼 수 있다.
왜 생성된 image의 색이 제한적일까? 이 시각화 방법을 이용해 실제 색상을 Visualization하려면 상당히 까다롭다. 실제 모든 image들은 0에서 255 사이의 값들로 이루어져야 한다. 이는 constrained optimization문제이다. constrained optimization은 제약 조건이 있는 상태에서 최적화를 수행해야 하는 문제를 뜻한다. 하지만 Gradient ascent와 같은 일반적인 방법들은 제약 조건이 없는(unconstrained) 경우이다. 따라서 시각화 할 때 나타나는 색상에 관련해서는 크게 신경을 쓸 필요가 없다.
만약 아무런 regularizer도 사용하지 않으면 어떻게 될까? Regularizer를 두지 않더라도 class score 를 최대화시키는 어떤 image가 생성되기는 할 것이다. 하지만 그 image는 아무것도 아닌 것처럼 보일 것이다. Random noise처럼 보일 뿐이다. 그렇긴 해도 그 image 자체가 가지는 아주 흥미로운 feature가 있다. 이는 나중에 더 자세히 배울 것이다. 어쨌든 이 image를 가지고는 Network가 어떤 것들을 찾고 있는지를 이해하기 힘들 것이다. 따라서 regularizer를 추가해서 image가 조금 더 자연스럽게 생성되도록 하는 편이 좋다.
Multimodality를 다루는 다른 방법은 없을지 고민할 수 있다. Multimodality란 같은 label인데 전혀 다른 pixel값을 가질 수 있는 image들이다. 당연히 있다. 시각화에 대한 본격적인 이야기는 이제 시작이다.
Multimodality: Jason Yesenski, et al
시각화의 다른 접근법들은 regularizer를 더욱 향상시키고 image를 더 잘 시각화시키는 방법에 관한 것이다. Jason Yesenski, et al의 논문이 있다. 이들은 아주 인상적인 regularizers를 추가했다.
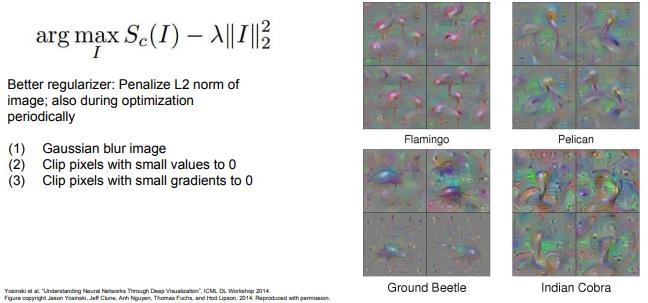
L2 norm constraint(제약)은 여전히 있다. 그리고 최적화 과정에 주기적으로 Gaussian-Blur를 적용한다. Gaussian-Blur란 image에 흐릿한 효과를 만들기 위해 image에 수학 함수를 적용한 것이다. 그리고 주기적으로 값이 작은 pixel들은 모두 0으로 만든다. Gradient가 작은 값들도 모두 0으로 만든다. 이는 일종의 projected Gradient descent라고 해석할 수 있다. projected Gradient descent란 제약 조건을 만족하도록 최적화 과정을 수행하는 것이다. 생성된 image를 더 좋은 feature를 가진 image 집합으로 주기적으로 mapping시키는 방법이다. 가령 Gaussian-Blur와 같은 smoothing 연산을 통해서다. 이 방법을 이용하면 훨씬 더 보기 좋은 image를 생성할 수 있다. 훨씬 더 깔끔해진다. 이처럼 괜찮은 성능의 regularizer를 추가하게 되면 생성되는 image가 조금 더 좋아질 수 있다.

이 과정은 최종 score 뿐만 아니라 중간 neuron에도 적용할 수 있다. 당구대 class의 score를 최대화시키는 것이 아니라 중간의 neuron을 최대화시키는 image를 생성해볼 수 있다.

위의 image들은 초기화된 image에 대해서 Network의 중간 Neuron을 최대화시키는 과정을 거쳐 출력된 image들이다. 어느 layer의 neuron을 주목 했는지에 따라 Layer 2, 3, 4, 5로 나뉜다. 이를 통해 각 layer의 neuron이 무엇을 찾고 있는지를 짐작해볼 수 있다. 여기 예제 image가 클수록 receptive field가 더 큰 Neuron들이다. Receptive field가 더 클수록 생성 가능한 image의 patch가 더 커진다. 이런 neuron들은 더 큰 구조와 더 복잡한 pattern을 찾는 image를 생성하는 경향이 있다.
이 논문에서는 최적화 과정 속에 multimodality를 아주 명시적으로 다루고 있다. 각 label마다 clustering 알고리즘을 수행한다. 하나의 label 내에 서로 다른 mode, 즉 image를 나타내는 다양한 관점의 image들끼리 다시 한번 class가 나뉜다. 이 mode들은 같은 class로 구별된다. 그리고 나뉜 mode들이 서로 가까운 곳에 가중치를 초기화해 최적화 과정이 다양한 mode들에 대해 더 효과적으로 탐색하고, 더 정확한 해답을 찾을 수 있도록 돕는 것이다. 이 방법을 통해서 multimodality를 다룰 수 있다. 쉽게 말하면 한 label을 더 세부적으로 판단하기 위해 다양한 하위 label인 mode를 둬서 분류하는 것이다.

직관적으로 보면, 가령 여기 있는 image들은 선반 위에 전시된 물건들을 close up 한 것이다. 이들의 label은 식료품점이다. 그리고 하단의 image들은 사람들이 식료품점을 돌아다니고 있는 모습이다. 이 또한 식료품점으로 labeling된다. 하지만 이 둘은 겉으로 보기에 아주 다르게 생겼다. 많은 label들이 이렇게 multimodality를 가지고 있다. Image를 생성할 때 이런 식으로 multimodality를 명시하게 되면 한 label에 대해 다양한 관점을 가진 생성 이미지를 얻을 수 있을 것이다.

Image 생성 문제에서 priors(사전 지식)을 활용하게 된다면 아주 리얼한 image를 만들어낼 수 있다. 위의 이미지들은 모두 ImageNet의 특정 class score를 최대화하는 image를 생성해낸 것이다. 기본 idea는 입력 이미지의 픽셀을 곧장 최적화하는 것 대신에 FC6를 최적화하는 것이다. 이를 위해서는 feature inversion network 등을 사용해야 하지만 이 이상 깊게 이야기하진 않겠다. 관심있는 사람들은 논문을 보라.
#### fooling image
Image pixel의 gradient를 이용해서 이렇게 image를 합성하는 방법은 아주 강력하다. 이를 통해 시도해볼 수 있는 아주 재미있는 것은 바로 fooling image(Network를 속이는 image)를 만들어내는 것이다. 우선 아무 image를 하나 고른다.

가령 코끼리 image를 골랐다고 하자. 그리고 Network가 이 image는 코알라 image라고 분류하도록 image를 조금씩 수정한다. 이렇게 코끼리 image를 조금씩 바꾸다 보면 Network는 이 image를 코알라 image라고 분류해버린다. 혹시라도 코끼리가 갑자기 귀여운 귀를 가진 코알라로 변신하는 모습을 상상할지 모르겠지만 사실은 그런 일이 일어나지 않는다. 코끼리를 가지고 코알라로 분류하도록 image를 바꿔보면 실제로는 2번째 image처럼 보인다. Network는 2번째 image를 코알라로 분류한다. 우리에게는 별반 차이가 없는데도 말이다. 배 image의 경우도 마찬가지로 오른쪽 사진을 아이팟으로 인식한다. 두 이미지 사이의 pixel값의 차이는 거의 없다. 우리는 pixel값의 차이에서 코알라나 아이팟의 feature라고는 찾아볼 수 없다. 그저 random한 pattern의 noise로 보인다. 어떻게 이런 일이 가능한 것일까? 이에 대해서는 Ian Goodfellow가 강연에 와서 설명해줄 것이다. (Lecture 16)
Visualizing: cause of birth
이런 식으로 중간 layer를 시각화하는 방법들은 Deep learning에 대한 비판에 대한 대응에서 유래한다. 비판이라 함은 “DL이라는 black box를 가지고 그걸 잘 최적화시켜서 좋은 결과가 나오는 건 알겠는데, 사실 결과를 믿진 못하겠어 DL의 결과가 어떻게 나왔는지를 당신조차 이해할 수 없잖아?” 와 같은 질문이다. 이런 많은 시각화 기법들은 왜 DL이 classification 문제를 더 잘 해결하는지를 사람들이 이해하기 위해 고안되♘다. DL 모델이 아무렇게나 분류하는 것이 아니라 의미 있는 행동을 하고 있음을 증명하려는 것이다. Image에 gradient를 update하는 방식으로 가능한 재미있는 idea가 하나 더 있다. “DeepDream”이다.
DeepDream(ver.cs231n)
DeepDream의 목적은 “재미있는 image를 만드는 것”이다. 부가적으로 model이 image의 어떤 feature들을 찾고 있는지를 짐작할 수 있다. DeepDream에서는 input image를 CNN의 middle layer까지 어느정도 통과시킨다. 그리고 역전파를 연산한다. 해당 layer의 gradient를 activation값으로 설정하고 역전파를 수행하며 image를 update한다. 이 과정을 계속 반복한다. 이는 Network에 의해 검출된 해당 image의 feature를 증폭시키려는 것으로도 해석할 수 있다. 해당 layer에 어떤 feature가 있던지 그 feature들을 gradient로 설정하면 이는 Network가 image에서 이미 뽑아낸 feature들을 더욱 증폭시키는 역할을 한다. 그리고 이는 해당 layer에서 나온 feature들의 L2 norm을 최대화시키는 것으로 볼 수 있다. L2 norm이란 각 image의 pixel의 값의 차이를 제곱해서 모두 더한 뒤 루트를 씌우는 연산을 의미한다. 여기에는 몇가지 trick이 존재한다.
1번째로 gradient를 연산하기에 앞서 image를 조금씩 움직이는 것이다. 원본 image를 그대로 network에 통과시키는 것 대신에 image를 2 pixel정도 이동시킨다. 이는 regularization 역할을 해서 자연스럽고 부드러운 image를 만들어준다. 그리고 여기에 L1 norm도 들어간다. 이는 image 합성 문제에서 아주 유용한 trick이다. 그리고 pixel값을 한번 clipping을 통해 image값을 0~255로 제한해주기도 한다. 이는 일종의 projected gradient decent인데 실제 image가 존재할 수 있는 공간으로 mapping시키는 방법이다. 이렇게 하늘 image를 가지고 알고리즘을 수행시키면 아주 재미있는 결과를 볼 수 있다.


하늘에 조그마한 특징들이 보일 것이다. 이들은 앞선 과정을 거쳐 증폭된 것들이다. 오른쪽 예제의 경우 왼쪽 예제에 비해 더 얕은 층의 layer로 만든 image이다.
DeepDream에 Multiscale을 가미해서 오랫동안 돌려보면 놀라운 것들을 볼 수 있다. 여기서는 multiscale processing을 수행한다. 작은 image로 DeepDream을 수행하고 점점 image의 크기를 늘려간다. 이런 식으로 점점 더 큰 image에 DeepDream을 수행하는 반복적인 과정을 거치는데 가장 큰 최종 scale로 수행하고 나면 다시 처음부터 이 과정을 반복 수행한다. 그 결과 아래와 같은 image를 얻을 수 있다.

지금 보이는 image는 ImageNet으로 학습시킨 Network로 만든 image이다. 다른 dataset으로도 만들어 볼 수 있다. 가령 MIT Paces Dataset으로도 해볼 수 있다. 1000 category의 객체를 가진 ImageNet 대신 200가지의 다양한 장면을 가진 dataset이다. 이 dataset에는 침실, 부엌과 같은 장면이 존재한다. MIT place로 학습시킨 네트워크를 가지고 DeepDream을 수행하면, 이와 같은 멋있는 시각화 이미지를 얻을 수 있다.
DeepDream(ver.my note)
DeepDream 알고리즘은 이미 훈련된 신경망 모델이 원본 이미지에서 특정 패턴을 더 부각해 몽환적이고 새로운 이미지를 만들어주는 방식으로 작동한다. Gradient descent(경사 하강법)이 아니라 Gradient ascent(경사 상승법)을 활용해 손실이 최대화되는 방향으로 input image의 pixel을 수정하며 훈련을 진행한다. Gradient descent가 손실을 최소화하는 방향으로 뉴런의 가중치를 조정하는 것과는 대비된다. 그런데 Deep dream의 모든 layer마다 손실이 최대화되도록 훈련하면 이미지가 너무 엉뚱해질 것이다. 특정 layer만 선택해 그 layer 위주로 이미지 픽셀을 수정하도록 훈련한다. layer마다 주목하는 부분이 다름을 활용해 image의 변환을 제한하는 방법이다. 다시 말하자면, DeepDream은 activate할 하나 이상의 layer를 선택해 손실이 커지도록 image pixel을 수정하며 선택한 layer를 “과잉해석”하게끔 하는 원리이다.
Feature inversion
Feature inversion 또한 Network의 다양한 layer에서 image의 어떤 요소들을 포착하고 있는지를 짐작할 수 있게 해준다. 어떤 image가 있고 이 image를 Network에 통과시킨다. 그리고 Network를 통과시킨 activation map을 저장한다. 그리고 이제는 이 activation map만 가지고 image를 재구성해볼 것이다. 해당 layer의 특징 벡터를 활용해 image를 재구성해보면, image의 어떤 정보가 feature vector에서 포착되는지를 짐작할 수 있다. 이 방법에서 또한 regularizer를 추가한 gradient ascent를 활용한다. Score를 최대화시키는 것 대신, feature vector간의 거리를 최소화하는 방법을 이용한다. 기존 image로 연산했던 특징 벡터와, 새롭게 생성한 image로 연산한 특징 벡터 간의 거리를 측정하는 것이다.
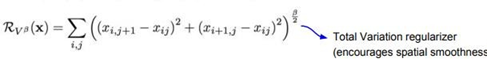
여기 사람들이 자주 사용하는 regularizer인 total variation이 있다. total variation는 상하좌우 인접 pixel간의 차이에 대한 패널티를 부여한다. 생성된 image가 자연스러운 image가 되도록 하는 것이다.

Feature inversion을 통한 시각화 예제를 살펴보자. 왼쪽은 원본 이미지이다. 코끼리 이미지와 과일 이미지가 있다. 이 이미지를 VGG-16에 통과시켜보자. 그리고 activation map을 기록하고, 기록된 activation map과 부합하도록 하는 새로운 image를 합성한다. 다양한 layer를 이용해서 합성한 image들을 통해서, 얼마나 많은 정보들이 저장되어 있는지를 짐작해 볼 수 있다. 가령 VGG-16 의 relu2_2를 거쳐서 나온 특징 벡터를 가지고 이미지를 재구성해보면 image가 거의 완벽하게 재구성됨을 알 수 있다. 이를 통해, relu2_2 에서는 image 정보를 엄청 많이 날려버리지는 않는다는 사실을 알 수 있다. 이제 Network의 조금 더 깊은 곳을 살펴보자. relu4_3 과 relu5_1을 가지고 재구성해 보면, image의 공간적인 구조는 잘 유지되고 있다는 것을 알 수 있다. 재구성된 image만 봐도 코끼리인지, 바나나인지, 사과인지 우리 눈으로도 구별할 수 있다. 하지만 디테일은 많이 죽♘다. 어떤 pixel인지, 어떤 color인지 정확히 알아보기 힘들다. 그런 low level의 디테일들은 Network가 깊어질수록 손실됨을 알 수 있다. 이를 통해서, Network가 깊어질수록 pixel값 같은 low level 정보들은 전부 사라지고, 대신에 color나 texture(image, 물체 표면의 미세한 무늬, 조직, 구조)와 같은 미세한 변화에 더 강인한 의미론적 정보들만을 유지하려 하는 것일지 모른다. 우리는 지금까지 계속 Style transfer를 배우기 위한 준비단계에 있다. Style transfer란 image의 style을 다른 image로 전달하는 기술로 두 image간의 시각적 특성, 예를 들면 색상과 texture등을 융합시키는 작업을 말한다.
#### Texture synthesis
Style transfer와 feature inversion 외에도 Texture synthesis(합성)과 관련된 문제들도 살펴볼 필요가 있다. Texture synthesis는 2개 이상의 image에서 texture를 추출해 하나의 image로 합성하는 작업을 의미한다. Texture synthesis 문제는 computer graphics 분야에서는 아주 오래된 문제이다. computer graphics란 컴퓨터를 사용해 image와 영상을 생성, 편집, 표현하는 기술과 분야를 의미한다.
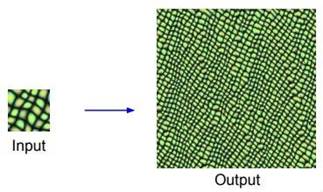
가령 여기 보이는 그림과 같은 input patch와 비슷한 비늘 패턴을 가진 더 큰 image를 만들어 내는 것이다. 가령 Nearest Neighbor와 같은 방법을 쓸 수 있다. 물론 Nearest Neighbor를 통한 Texture synthesis 방법들도 상당히 좋은 편이다. 이 방법은 신경망을 사용하지 않고 scan line을 따라서 한 pixel씩 image를 생성해 나가는 방법이다. 현재 생성해야 할 pixel 주변의 이미 생성된 pixel들을 살펴본다. 그리고 input patch에서 가장 가까운 pixel을 연산해 input patch로부터 한 pixel을 복사해 넣는 방식이다. 주변 pixel값의 분포를 분석해 비어 있는 부분을 채우는 방식이다.
기본적인 수준의 간단한 Texture synthesis는 신경망 없이도 할 수 있다. 하지만 복잡한 texture에서는 상황이 조금 다르다. 단순하게 input patch에서 복사하는 방식은 잘 동작하지 않는다. 2015년에 신경망을 활용해 Texture synthesis문제를 해결하는 시도가 처음 있♘다. 이 방법은 우리가 앞서 살펴본 feature map을 이용한 gradient ascent와 매우 유사하다. 이 방법은 Neural texture synthesis를 구현하기 위해서 Gram matrix라는 개념을 이용한다.
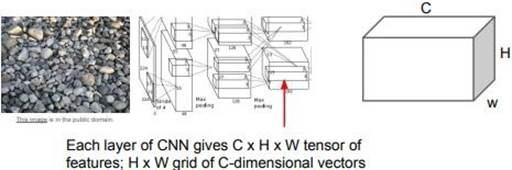
이 방법에서는, 가령 input texture로 자갈 사진을 넣는다. 이 사진을 Network에 통과시킨 후, Network의 특정 layer에서 feature map을 가져온다. 이렇게 가져온 feature map의 크기는 CxHxW 이다. HxW grid는 공간 정보를 가지고 있다. HxW의 한 점은 해당 지점에 존재하는 image의 feature를 담고 있다고 할 수 있다. 이제 이 activation map을 가지고 input image의 “textual descriptor”를 계산한다. “textual descriptor”란 image나 video와 같은 비구조적인 data를 특정한 형태의 text로 표현하는 기술을 말한다.
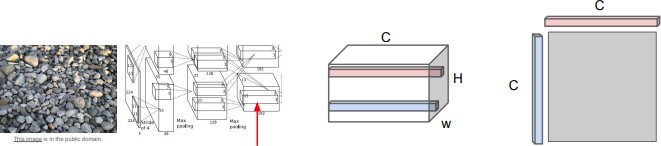
우선 activation map에서 서로 다른 2개의 feature vector를 뽑아낸다. 각 feature vector는 C차원 벡터이다. 이 두 벡터의 outer product(외적)을 연산해서 CXC Matrix를 만든다. 이 CXC Matrix는 image 내 서로 다른 두 pixel에 있는 C개의 features간의 co-occurrence를 담고 있다. co- occurrence 란 두 가지 이상의 요소가 함께 나타나는 빈도를 나타내는 통계적 개념이다. 가령 C x C 행렬의 (i, j) 번째 요소의 값이 크다는 것은 pixel m의 i번째 feature와 pixel n의 j번째 feature가 모두 크다는 의미이다. 이를 통해서 서로 다른 image patch에서 동시에 활성화되는 특징이 무엇인지 second moment를 통해 어느정도 포착해 낼 수 있다. second moment란 확률론에서 사용되는 개념으로, data의 Variance와 관련된 값이다. Data가 어떤 분포를 가지고 있는지, data의 변동성이 얼마나 큰지를 알아보는데 사용된다.
이 과정을 H x W grid에서 전부 수행해주고, 결과에 대한 평균을 계산해보면 C x C Gram matrix를 얻을 수 있다. 그리고 이 결과를 input image의 “textual descriptor”로 활용한다. Gram matrix의 흥미로운 점은 공간 정보를 모두 날려버렸다는 것이다. 이미지의 각 지점에 해당하는 값들을 모두 평균 냈기 때문이다. 공간 정보를 다 날려버린 대신에 feature들 간의 co-occurrence만을 포착하고 있다. 때문에 gram matrix는 “textual descriptor”로 아주 제격이며 계산 또한 효율적이다.
C x H x W 차원의 3차원 Tensor가 있다고 해도 행렬을 C x(HW)로 바꾼 다음에 한 번에 연산할 수 있다. 매우 효율적이다. 혹시, 왜 제대로 된 Covariance matrix(공분산 행렬)을 쓰지 않고 gram matrix를 사용하는지 궁금할 수도 있다. Covariance matrix란 데이터 셋의 두 변수 간의 상관 관계를 나타내는 행렬이다. 물론 Covariance matrix를 써도 무방하고, 실제로 동작도 잘 한다. 하지만 Covariance matrix를 계산하는 것 자체가 비용이 너무 크다. 실제로 사람들은 공분산 행렬 보다는 gram matrix를 선호하는 편이다.
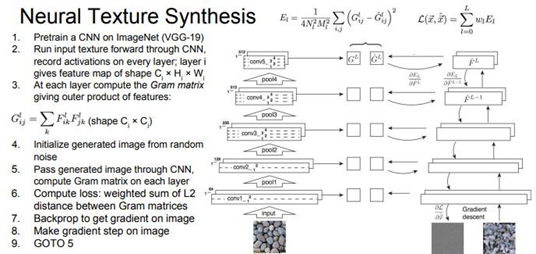
이제 textual descriptor(텍스트 기술자)를 만들♘으니 이미지를 생성할 차례다. 이는 gradient ascent procedure(구조)와 유사한 과정을 거친다. Texture synthesis도 앞서 슬라이드에서 접했던 특징 재구성(feature reconstruction)과정과 유사하다. 다만 입력 이미지의 특징 맵 전체를 재구성하기 보다는 gram matrix를 재구성하도록 하는 것이다. 실제로 거치는 단계는, 우선 feature inversion에서 했던 것처럼 pretrained model를 다운로드 받는다. 많은 사람들이 VGG model을 선호한다. 그리고 이미지를 VGG에 통과시키고 다양한 layer에서 gram matrix를 계산한다. 그리고 생성해야 할 이미지를 랜덤으로 초기화시키고, 그 다음 과정부터는 gradient ascent와 유사하다.
다시, 우선 이미지를 VGG에 통과시킨다. 그리고 여러 layer에서 gram matrix를 계산한다. 그리고 원본 이미지와 생성된 이미지의 gram matrix간의 차이를 L2 norm을 이용해 Loss로 계산한다. 그리고 Loss를 역전파를 통해 생성된 image의 pixel의 gradient(픽셀이 얼마나 gram matrix에 영향을 미치는지)를 계산한다. 그리고 gradient ascent를 통해 image pixel을 조금씩 업데이트한다. 이 과정을 여러 번 반복한다. 다시 앞 단계로 가서 gram matrix를 계산하고, Loss를 계산하고 역전파를 수행한다. 이 과정을 거치면 입력 texture와 유사한 texture를 생성할 수 있다.

NIP’15에 실린 논문은 독일의 한 연구소에서 나왔다. 텍스처 합성 결과가 아주 뛰어나다. 맨 위 의 이미지를 보면 4가지의 서로 다른 입력 texture를 볼 수 있다. 그리고 아래 쪽은 gram matrix를 이용한 texture synthesis를 보여준다. pretrained CNN의 다양한 layer에서 gram matrix를 계산한 결과이다. 얕은 layer에서의 결과를 보면, 이미지가 색상은 잘 유지하고 있지만 공간적인 구조는 잘 살리지 못한다. 레이어가 더 깊어질수록, 이미지의 주요 패턴들을 아주 잘 재구성해 내는 것을 볼 수 있다. 결과가 상당히 좋다. 입력 patch의 패턴과 아주 유사한 새로운 이미지를 아주 잘 합성해 낼 수 있다. 앞서 보여줬던 Nearest Neighbor 기반의 방법과는 확연히 다른 결과들을 볼 수 있다. 보통 Loss는 gram matrix를 다양한 layer에서 연산하고 가중 합을 통해 최종 loss를 구한다. 위 슬라이드의 경우에는, 각 layer의 특징을 강조하기 위해서, 오로지 한 layer로만 gram matrix를 계산한 것이다.

이 텍스처 합성을 자연물이 아니라 예술작품에 적용하면 어떻게 될까? 우선 gram matrix를 이용한 texture synthesis는 그대로 가져간다. 여기에 Starry night(Van Gogh) 이나 Muse(Picasso)를 텍스처 입력으로 사용하면 어떻게 될까? 이들을 입력 texture로 두고 같은 알고리즘을 수행해보자. 생성된 이미지를 보면, model이 예술 작품의 아주 흥미로운 부분들을 재구성해 내는 경향을 알 수 있다. texture synthesis와 feature inversion을 조합하면 아주 흥미로운 일이 벌어진다. 이 아이디어가 바로 style transfer다.
Style transfer

Content Image는 Network에게 우리의 최종 이미지가 어떻게 “생겼으면 좋겠는지” 알려준다. Style Image는 최종 이미지의 “texture가 어땠으면 좋겠는지” 을 알려줍니다. 최종 이미지는 content image의 feature reconstruction loss도 최소화하고 Style image의 gram matrix loss도 최소화하는 방식으로 최적화하여 생성해낸다. 이 두가지 Loss를 동시에 활용하면, style image스러운 화풍의 content image가 생성됩니다. network에 content/style 이미지를 통과시키고 gram matrix와 feature map을 계산한다. 최종 출력 이미지는 랜덤 노이즈로 초기화시킨다. forward/backward를 반복하여 계산하고 gradient ascent를 이용해서 이미지를 업데이트한다. 수백번 반복하면 아주 아름다운 이미지를 얻을 수 있게 된다.
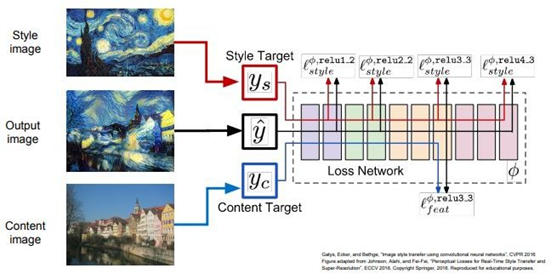
Style Transfer는 DeepDream에 비해서 이미지를 생성할 때 컨트롤할 만한 것들이 더 많다. DeepDream의 경우 어떤 것들을 만들어낼지 컨트롤할 만한 요소가 많이 부족하다. network에 layer와 반복 횟수 정도만 조절하면 “개 달팽이(dog slug)”가 이미지 전체에 퍼질 뿐입니다. 반면 Style Transfer의 경우 원하는 결과를 만들기 위해 정밀 조절한 것들이 조금 더 많다.

동일한 content image라고 할지라도 다양한 style images를 고르게 되면 전혀 다른 이미지들이 생성된다.

hyperparameter도 자유롭게 조정할 수 있다. style/content loss의 joint loss이기 때문이다. Joint loss란 일반적으로 2개 이상의 서로 다른 loss function을 결합(+)해 사용하는 것을 말한다.

style/content loss간의 가중치를 조절하면, 내가 어디에 더 집중해서 만들 것인지를 조절할 수 있다. 또 다른 hyperparameter도 존재한다. 가령 gram matrix를 계산하기 앞서 style image를 resizing해서 넣어준다면 Style image로부터 재구성된 특징들의 스케일을 우리 마음대로 조절할 수 있을 것이다. 위의 이미지들은 다른 것들은 전부 같은 세팅이고 다만 style image의 사이즈만 달라진 경우다. Style image의 사이즈를 조절하는 것이 조절할 수 있는 또 하나의 축이 될 수 있다.

또한 여러 장의 style images를 가지고 style transfer를 할 수도 있다. 동시에 여러 style loss의 gram matrix를 계산하는 것이다. 결과도 아주 좋다.

앞서 DeepDream에서 multi-scale processing을 통해 아주 멋진 고해상도 이미지를 얻을 수 있♘다. multi-scale processing을 style transfer에도 적용해 볼 수 있습니다. 이 이미지는 Starry night로 랜더링된 4K Stanford 이미지입니다. 사실 고해상도 이미지를 만드는 것은 계산량이 상당하다. 4K 이미지를 위해 GPU 네 개를 사용했다. 아주 비싼 연산이다.

또 다른 재미있는 방법도 있다. 사실 Style Transfer와 DeepDream을 조합해 볼 수도 있다. content loss + style loss + DeepDream loss(L2 norm 최대화)를 조합하는 것이다. 결과는 다음과 같다. “개 달팽이(dog slug)” 가 사방에 퍼져있는 Van Gogh 그림이다.
Style transfer 알고리즘의 가장 큰 단점은 아주 느리다는 것이다. 이런 이미지를 만들어 내려면 backward / forward를 아주 많이 반복해야 한다. 게다가 앞서 보여준 4K 이미지를 만들려면 메모리와 계산량이 엄청나게 크다. 엄청 좋은 GPU를 쓰더라도 이미지 한 장을 만드는데 수십 분이 소요된다.
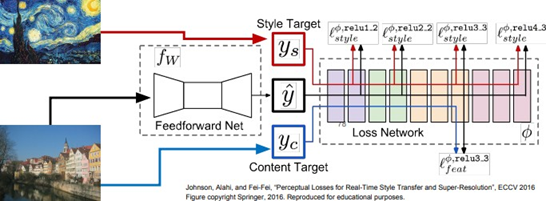
해결책이 있다면, Style transfer를 위한 또 다른 네트워크를 학습시키는 것이다. 2016년에 나온 논문이다. 애초에 Style image를 고정시켜 놓는다. 이 경우 Starry night 이다. 이 방법은 합성하고자 하는 이미지의 최적화를 전부 수행하는 것이 아니라 Content image만을 입력으로 받아서 결과를 출력할 수 있는 단일 네트워크를 학습시키는 방법이다. 이 네트워크의 학습 시에는, content/style loss를 동시에 학습시키고 네트워크의 가중치를 업데이트한다. 학습은 몇 시간이 걸릴 수 있지만, 한번 학습시키고 나면 이미지를 네트워크에 통과시키면 결과가 바로 나올 수 있다. 이 코드는 온라인에 있다. 영상 퀄리티는 기존의 방법과 거의 유사하면서 몇 천배 빠르게 동작한다. 이 네트워크가 아주 효율적이기 때문에 좋은 GPU을 사용하면 네 가지 스타일을 동시에 돌려볼 수도 있을 것이다.
우리는 오늘 CNN representations을 이해할 수 있는 다양한 방법들을 배웠다. 우선 activation 기반의 방법들이 있♘다. nearest neighbor, dimensionality reduction, maximal patches, occlusion images등 Activation values를 기반으로 해당 feature가 무엇을 찾고 있는지를 이해하는 방법이 있다.
우리는 또한 gradient기반의 방법도 배웠다. gradients을 이용해서 새로운 이미지를 만들어내는 방법이있다. saliency maps, class visualizations, fooling images, feature inversion이 있다. 그리고 아주 멋있는 이미지들을 생성해내는 Style Transfer/DeepDream을 알아보았다.
Leave a comment